الإعلان عن WebCeph
يسرّني الإعلان عن مشروعي الجديد: WebCeph، تطبيق ويب مجّانيّ لترسيم الصور السيفالومتريّة وتحليلها.
ما معنى هذا؟
الصور السيفالومترية (cephalometric radiographs) هي صور شعاعيّة تستخدم الأشعّة السّينيّة (X-ray) يستخدمها أطباء تقويم الأسنان (orthodontists) لتقييم المشاكل المتعلّقة بالفكّين والجمجمة عند المريض، حيث تدرس مجموعة من الزوايا والأبعاد الّتي تُقاس بين نقاط تُعيّن في مواضع محدّدة على الصّورة الشّعاعيّة.
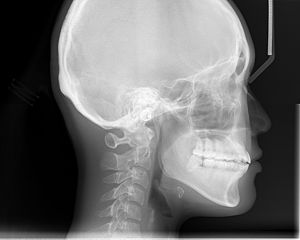
صورة شعاعية سيفالومترية Wikipedia
لتوضيح الفكرة لغير المختصين، لنأخذ النّقاط N وS وA مثالًا:
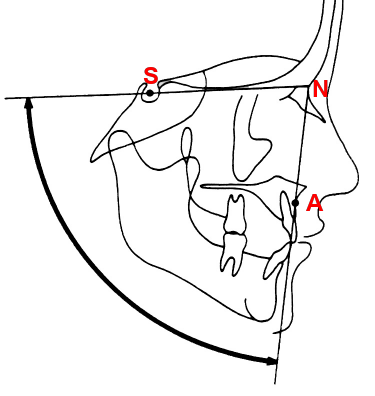
الزّاوية SNA تُعبّر عن تقدّم أو تراجع الفكّ العلويّ
- النقطة N تُعرّف على أنّها النّقطة الأكثر أماميّة على الدّرز بين العظمين الجبهي والأنفي
- النقطة S هي مركز السّرج التركي
- النقطة A هي أعمق نقطة على الوجه الأمامي لعظم الفكّ العلويّ
عند رسم خطّين بين هذه النقاط يتشكّل لدينا زاوية هي SNA، تُعبّر هذه الزّاوية عن مدى تقدّم الفكّ العلويّ، وفي حال تجاوز 84 درجة فإنّها تعني تقدم الفكّ العلويّ بصورة غير طبيعيّة، وبالعكس، فإنّ قيمة أقل من 80 لهذه الزّاوية تعني تراجع الفكّ العلويّ بصورة غير طبيعيّة، وفي كلا الحالتين قد هذا يؤثّر على المظهر العامّ للمريض، كما أن معالجة الحالة تختلف باختلاف المشكلة بالطّبع.
هناك زوايا كثير وقياسات خطّيّة يمكن إنشاؤها ودراستها على الصّورة السّيفالومتريّة، وكل قياس خارج عن المدى المقبول قد يُشير إلى وجود مشكلة ما في عظام الجمجمة أو الجلد والشّفاه.
تتوفّر الكثير من التّحاليل السيفالومتريّة الّتي قدّمها بعض من أشهر أطباء تقويم الأسنان في القرن الماضي والقرن الحالي، ومنها تحليل Downs، وتحليل Steiner، وتحليل Björk وغيرها.
تختلف هذه التحاليل في النقاط والمستويات الّتي تعتمدها، وكذلك في ما يُعتبر قيمًا «طبيعيّة» للزوايا والقياسات الخطّيّة، وذلك لأنّ الحالات الطّبيعيّة الّتي اعتمدت للوصول إلى هذه القيم تنتمي لمجموعات عرقيّة مختلفة.
الفكرة من التطبيق
يُجرى التّرسيم السّيفالومتريّ عادةً على ورق شافّ يُلصق فوق الصّورة المطبوعة، وتّعيّن عليه النقاط والخطوط ثمّ تقاس الزّوايا والأبعاد المطلوب تحليلها.
تتوفّر أيضًا برامج تجاريّة تسمح بإجراء التّحليل على النّسخة الرّقميّة من الصّورة.
إذا أردنا مقارنة التحليل اليدويّ بالتحليل على الحاسوب،
- فلا شكّ أنّ التحليل اليدويّ يستغرق وقتًا أطول، فالتحليل على الحاسوب يسمح بتعديل مواضع النقاط بعد رسمها بسهولة وإجراء أي تصحيح مرغوب، كما أنّه يسمح لنا بالتّبديل بين التّحاليل المختلفة واستعراض النّتيجة مباشرةً؛
- وقد يكون التحليل اليدوي أقل دقّة بسبب حجم رأس القلم أو بسبب عدم القدرة على تكبير الصّورة لرؤية مواضع النّقاط بصورة أوضح؛ هذا بالإضافة إلى صعوبة قياس الزّوايا بفواصلها العشريّة بالأدوات الهندسيّة التّقليديّة.
يزيد WebCeph التحليل سهولة وذلك بتحويل التحليل إلى مجموعة من النّقاط المُرتّبة الّتي ينفذها المُستخدم واحدة تلو الأخرى حتى النهاية، ويقوم برسم الخطوط والزّوايا تلقائيًّا، وعندها نعرض نتائج التحليل ودلالات كل قيمة.
ميّزات التّطبيق حاليًّا
- اختيار التّحليل المرغوب وإجراؤه وفق خطوات مرتّبة
- ترسيم تلقائيّ للخطوط والزّوايا
- حساب قيم الزّوايا مباشرةً
- إمكانيّة محو أيّ نقطة وإعادة تعيينها
- إمكانيّة عكس الصّورة
- ملخّص لنتائج التّحليل وتفسير القيم المحسوبة (الصّنف الهيكلي، نموذج النّمو، العضّة الهيكليّة، البروفيل الجانبي… إلخ.)
- تطبيق ويب، بمعنى أنّه يعمل بمجرّد زيارة الموقع دون الحاجة لتثبيت أي برنامج على الحاسوب
- يعمل بلا اتّصال بالإنترنت بعد الزّيارة الأولى باستخدام وصفة سحريّة وبعض الحيل البرمجيّة 🎉
- إمكانيّة تصدير الصّورة السّيفالومتريّة مع التّرسيم في ملفّ واحد وإعادة عرضها باستخدام التّطبيق ذاته
استعراض التطبيق
خلال تطوير التطبيق كنت حريصًا على جعل تجربة استخدامه مفهومة ومباشرة، ولذلك قمت بجعل معظم الصّفحة مكانًا لسحب الصّورة الشّعاعيّة وإسقاطها، مع ترك الخيار بانتقاء الملفّ بالطّريقة التّقليديّة في حال لم يُدرك المُستخدم طريقة إسقاط الصّورة، تذكّر أنّ البرنامج موجّه لأطباء، وليس لخبراء باستعمال الحاسوب.
شريط التّعديلات أسفل منطقة الإسقاط تُرك عمدًا قبل عرض الصّورة ليفهم الطّبيب ما طبيعة الأدوات المتاحة له عندما يبدأ التّرسيم.
الجانب التقني
يمكن أن أقول إنّ هذا أضخم مشاريعي البرمجيّة حتّى الآن، وفي لحظة كتابة هذه التّدوينة، بلغ عدد الإيداعات (commits) في مستودع git نحو 360 إيداعًا وعدد الفروع 23 فرعًا. كما أنّه أوّل مشروع جادّ أكتبه لأنّني أحتاجه في حياتي العمليّة، وكذلك هو أوّل مشروع أكتبه بـTypeScript، وإضافةً إلى ذلك، استخدمت React وRedux.
في ما تبقّى من هذه المقالة سأناقش التّقنيات الّتي اخترتها لهذا المشروع، والأسباب الكامنة وراء كلّ اختيار.
لماذا اخترت TypeScript؟

لغة TypeScript من Microsoft
ربّما يعرف القرّاء أنّ JavaScript هي لغتي المُفضّلة والّتي أكتب بها منذ نحو 4 سنوات، وفي كلّ مرة يُثار موضوع اللّغات الّتي تحوّل إلى JavaScript فإنّني أقف في صف المعترضين على استخدام هذه اللّغات، وفي الحقيقة كانت المبرّرات حينها قويّة، ولعلّ أبرزها:
- تعقيد عمليّة التنقيح (Debugging)
- الحاجة لاستخدام أداة بناء لتحويل النّصّ البرمجيّ إلى JavaScript
- بعض اللّغات مثل CoffeeScript، تستخدم صياغة (syntax) غريبة قد تكون مألوفة للقادمين من Python وRuby، لكنّها مختلفة كلّ الاختلاف عن JavaScript
- عادة يكون استخدامها غير ضروريّ ولا تقدّم شيئًا جديدًا سوى تسهيل كتابة النّصّ البرمجيّ قليلًا أو تجنّب بعض الأخطاء الّتي يمكن تجنبّها بشيء من الحذر
- تطوّر هذه اللّغات مرهون برغبة وفراغ من يعمل عليها، وقد يحرمك هذا من استخدام ميّزات جديدة في الإصدارات المستقبليّة في JavaScript
- قد تتعارض هذه اللّغات مع ميّزات مستقبليّة في JavaScript وهذا يعني الحاجة لتعديل بعض النّصّ البرمجيّ أو إيجاد طرق أخرى لحلّ التّعارض
على الرّغم من كلّ هذا، لم أتردّد للحظة في اعتماد TypeScript كلغة أساسيّة لـWebCeph، فعالم التّطوير للويب شديد التّغيّر وبعض هذه الأسباب لم يعد صالحًا، فمثلًا:
- أصبح من المعتاد اليوم استخدام أداة بناء لتطوير تطبيقات الويب، وخصوصًا الضّخمة منها، حتّى وإن كان المشروع مكتوبًا بـJavaScript، فإنّك ما تزال تحتاج هذه الأدوات لجمع الملفّات وتقليصها وتجزئتها… إلخ.
- شاع استخدام ES6 لكتابة تطبيقات الويب على الرّغم من أنّ المتصفّحات لا تدعمها بالكامل، وعلى الرّغم من وجود متصفّحات قديمة لا تدعمها نهائيًّا وما تزال قيد الاستخدام، وهذا يعني أنّنا نحتاج إلى تحويل ES6 إلى ES5، أيّ أنّنا نحتاج لأداة تحويل مثل Babel بأيّة حال.
- عصفت React بعالم تطوير الويب في السّنوات القليلة الماضية وشاع معها استخدام JSX، الأمر الّذي يبرّر الحاجة لاستخدام أداة بناء أيضًا.
- اللّغات قويّة الأنواع مثل TypeScript وFlow تُقدّم شيئًا جديدًا بالفعل، وخصوصًا للمشاريع الضّخمة، فوجود الأنواع:
- يقلل الأخطاء وقت التّنفيذ (runtime errors) باكتشافها وقت البناء (compile time)
- يستطيع محرّر يفهم اللّغات ذات الأنواع مثل Visual Studio Code أن يُساعدك في اكتشاف الأخطاء لحظة بلحظة أثناء كتابة النّصّ البرمجيّ، كما يستطيع فهم العلاقات بين الكائنات والبحث عن المواضع الّتي أُشير فيها إلى هذه الكائنات في كامل المشروع. كما أنّ فهم هذه الأنواع يسمح للمحرّر بإعادة تسمية الكائنات وخصائصها في كلّ المشروع (refactoring) بضغطة زرّ! وهذا شيء لم أكن لأتخيّله في JavaScript.
- وجود الأنواع لا يُلغي الحاجة لإجراء اختبارات الوحدات والتكامل (unit and integration tests) لكنّه حتمًا يجعل حياتك كمطوّر أقل معاناة! صدّقني!
- صياغة TypeScript شبيهة جدًّا بصياغة JavaScript، في الحقيقة فإنّ TypeScript هي superset لـJavaScript، أيّ أنّ كلّ نصّ برمجيّ مكتوب بـJavaScript هو نصّ TypeScript سليم الصّياغة.
- تطوّر TypeScript يسير خطوة بخطوة مع تطوّر JavaScript، كما أنّ TypeScript تتضمّن بعض الميّزات من المرحلة 3 في معيار ECMAScript القادم، بمعنى أنّها تسبق تطوّر JavaScript وتسمح للمُطوّرين بتجربة بعض الميّزات شبه المُستقرّة.
ربّما يكون السّبب الأهم الّذي جعلني أعتمد TypeScript بدل JavaScript هو إدراكي لضخامة المشروع منذ البداية، ووجود الأنواع سيُساعدني في توسعة المشروع (scaling) مع الإبقاء على إمكانيّة صيانته (maintainability). لا أستطيع تخيّل حجم العناء الّذي كنت سأكابده لو اعتمدت JavaScript وأنا أحاول تتبّع مصدر الخطأ بين مئات الملفّات!
Visual Studio Code
محرّر النّصوص البرمجيّة Visual Studio Code من Microsoft
لديّ تجربة سيئّة مع بيئات التّطوير (IDEs) خصوصًا المُعتمدة على Java مثل Eclipse وAndroid Studio، فهي ثقيلة وبطيئة، ولو كان عليّ الاختيار بين كتابة النصّ البرمجيّ بلغة Assembly على أوراق البُرديّ أو أن أبني مشروعًا في Eclipse لما تردّدت لحظة في البحث عن أوراق البرديّ!
بعيدًا عن المُزاح، فإنّني بالفعل أفضّل استخدام المُحرّرات البرمجيّة الخفيفة مثل Sublime Text، وللأسف فإنّ Atom وعلى الرّغم من أنّه ليس بيئة تطوير بالمعنى الحقيقيّ، إلّا أنّه ثقيل وبطيء! لهذا استمررت في استخدام Sublime Text حتّى تغيّر كلّ شيء بإطلاق Visual Studio Code.
بعض ما يقدّمه Visual Studio Code:
- إكمال تلقائيّ ذكيّ للتّعليمات، يعتمد على معرفته لأنواع الكائنات وخصائص والوظائف المُتاحة فيها
- الّذهاب إلى موضع تعريف النّوع المُستخدم من أيّ مكان بالمشروع (Go to definition)
- البحث عن أي استخدام لأيّ كائن في أي ملفّ ضمن المشروع (Find All References)
أستطيع أن أقول إنّ VS Code كان عاملًا أساسيًّا في إنجاز WebCeph، فهو يجمع الخفّة والسّرعة من المُحرّرات البسيطة مع الذّكاء وقابليّة التّوسيع الّتي تتمتّع بها بيئات التّطوير، بإمكانه مثلًا أن يفهم الأنواع الّتي تكتبها وكيف تتوزّع الكائنات والوحدات في مشروعك، وبإمكانه تنبيهك بشكل فوريّ في حال لم ينطبق كائن ما مع النّوع الّذي يستخدمه، ويستطيع أيضًا إعادة تسمية الكائنات عبر كامل المشروع وفيه طرفيّة مُدمجة وإمكانية إدارة مستودع git ومئات السّمات والإضافات.
ولكنّ الأهمّ من ذلك هو المحرّك الّذي يعمل وراء هذا الذّكاء، وهو Language Server Protocol، بروتوكول وضعته Microsoft وطرحته كمعيار (standard) مُتاح للجميع، وهو يسمح لأيّ مُحرّر بفهم النّص البرمجيّ المكتوب بأيّة لغة بمجرّد إنشاء خدمة لغة تعمل في الخلفيّة وتقدّم للمُحرّر المعلومات اللّازمة عن الكائنات والملفّات. أعتقد أنّ هذا البروتوكول سيُحدث ثورة في أدوات التّطوير لم نشهدها منذ عشرات السّنين، وقد بدأت بعض اللّغات ببناء خدمات لغة، كما أنّ بعض المحرّرات الأخرى بدأت بتبنّي هذا البروتوكول لتصبح بنفس الذّكاء.
وكذلك فإنّه يتكامل بصورة ممتازة مع TypeScript ليقدّم نفس الذّكاء للأنواع الّتي تُنشؤها بنفسك.
كما ترى فإنّني استخدم TypeScript وVS Code في مشروعي، وكلاهما من Microsoft وذلك على حاسوبي الّذي يعمل بنظام Linux ويبدو فعلًا أنّ Microsoft جادّة في فرض صورتها الجديدة على أنّها من أنصار المصادر المفتوحة. والمتابع لأخبار Microsoft لم يستغرب كثيرًا خبر انضمامها إلى مؤسّسة Linux مؤخّرًا.
لماذا لم أعتمد Flow؟
Flow هي أداة تُضيف التّحقّق من الأنواع إلى JavaScript
في عالم اللّغات ذات الأنواع الّتي تتحوّل إلى JavaScript، لدينا منافس آخر قادم من Facebook، هو Flow، وهي لغة شبيهة جدًّا بـTypeScript من حيث الصّياغة، لكنّني لم أخترها لأنّها أحدث عهدًا من TypeScript، كما أنّ إعدادها كان أكثر تعقيدًا كون خادوم اللّغة مكتوبةً بلغة OCaml وتحتاج لتثبيت الملفّ التّنفيذي الموافق لنظامك؛ أمّا TypeScript فهي مكتوبة بـTypeScript أيّ أنّها لغة ذاتيّة الاستضافة (self-hosted) وتثبيتها أقلّ تعقيدًا كونّها لا تحتاج ملفًّا تنفيذيًّا مُصنّفًا (compiled) بحسب النّظام والمعماريّة.
لا أرى اختلافًا كبيرًا بين اللّغتين، وكلاهما تقدّمان ميّزات متشابهة، إلّا أنّني ربّما قد أتحوّل لاستخدام Flow في مشاريع مستقبليّة حسب وتيرة تطوير كلا اللّغتين، أو ربّما على سبيل التّعلّم.
حاليًّا أتابع تطوّر TypeScript من قُرب ولعلّي أتفرّغ لكتابة تدوينة عنها وعن بعض التّحدّيات الّتي واجهتني أثناء استخدامها، خصوصًا فيما يتعلّق بالمكتبات المكتوبة بـJavaScript الخالية من الأنواع واستخدامها ضمن TypeScript.
لماذا اخترت React؟
مكتبة React من Facebook
ما من مُتابع لعالم تطوير الويب في السّنوات الماضيّة إلا وقد سمع بـReact، مكتبة تطوير الواجهات الّتي تستخدمها Facebook في نسخة الويب من موقعها، وأتاحتها كمشروع مفتوح المصدر للعموم، ومنذ ذلك الحين أستطيع أن أقول بثقة أنّ تجربة تطوير الويب من منظور مُطوّر الويب قد تغيّرت تمامًا، كما أنّها أتاحت لمستخدمي الويب الحصول على تطبيقات ويب أذكى وأسرع وأكثر كفاءة؛ وأسباب ذلك كثيرة، لكنّني أعتقد جازمًا أنّه وعلى الرّغم من أنّ عالم تطوير الويب لا يستقرّ على مكتبة واحدة إلّا لفترة قصيرة، إلّا أنّ الأفكار الّتي أتت بها React أو مهّدت لها بشكل مباشر أو غير مباشر قد غيّرت من مسار تطوير الويب للأبد. سأستعرض فيما يلي بعض الأسباب الّتي تجعلني أفضّل React على أيّة مكتبة أخرى.
React ليست إلا مكتبة
Do one thing and do it well
React ليست إطار عمل، بل مكتبة، فهي تفعل شيئًا واحدًا وتفعله بإتقان، هذا الشيء هو عرض الواجهات (كما تقول الصّفحة الرّئيسيّة للمكتبة)، وهذا قد يكون غير مرغوب لبعض المطوّرين الّذين يُفضّلون أطر عمل مُتكاملة لإنجاز أعمالهم بسرعة، إلّا أنّه يُعطي المُطوّر كامل الحرّيّة في استخدام أيّة مكوّنات أخرى قد يرغب باستعمالها مع React دون فرض مكوّن مُعيّن، سواء كان هذا المُكوّن مسؤولًا عن إدارة بيانات تطبيقك (state management) أو التّعامل مع البيانات الخارجيّة (data fetching)؛ وربّما يكون هذا سرّ الشّعبيّة الكبيرة الّتي نالتها React. شخصيًّا أنا من أنصار فسلفة Do one thing and do it well، وتبدو React اختيارًا بديهيًّا لي، لأنّني أفضّل «تركيب» الأشياء مع بعضها بنفسي وفهم كيف تعمل هذه المُكوّنات معًا.
كلّ شيء هو مُكوّن (Everything is a Component)
فكرة تنظيم أجزاء الواجهة في مُكوّنات ليست جديدة، في Angular 1 كان لدينا شيء مشابه يُسمّى الموُجّهات (directives)، ولدينا أيضًا مجموعة من التقنيّات القادمة للمتصفّحات تحت عنوان مُكوّنات الويب (Web Components)، وعليها بُنيت مكتبة Polymer من Google.
تنظيم الواجهة في مكوّنات يجعلها قابلة لإعادة الاستخدام في أكثر من موضع وربّما في أكثر من مشروع إن أحسنت عزلها وفصل ارتباطها عن بعضها (decoupling)، تدفع React فكرة المكوّنات إلى صميم مشروعك، فكلّ عنصر مرئي لا بدّ أن يكون مكوّنًًا، ويمكنك تنظيم هذه المكوّنات في ملفّات وتعيين أنواع البيانات الّتي تحتاجها.
JSX
الجزء الثاني المهمّ في React هو طريقة كتابة المكوّنات وجمعها مع بعضها، حيث وفّرت Facebook مع React لغة تُسمّى JSX تسمح لك بإنشاء المُكوّنات بطريقة مُشابهة لكتابة الوسوم في HTML وذلك ضمن JavaScript مباشرةً، ومع أنّ هذه الفكرة لقيت معارضة شديدة من بعض المُطوّرين المُتمسّكين بفكرة «الفصل بين الاهتمامات (separation of concerns)» الّذين يرون أنّ لكلّ لغة اختصاصًا ولا يجب أن تختلط JavaScript مع HTML أو CSS إلّا أنّه يبدو أن الاتّجاه العام يسير نحو فهم أنّ الفصل بين الاهتمامات لا يعني بالضّرورة الفصل بين اللّغات، وإنّما جمع كل الأجزاء المُتعلّقة بجانب مُعيّن من التّطبيق في مكان واحد وفصلها عن الأجزاء الأخرى، وذلك بغض النّظر عن اللّغة المُستعملة. تبدو لي هذه الفكرة منطقيّة تمامًا ولا أرى مُبرّرًا لرفضها، فاللّغة ليست إلّا وسيلة. بالطّبع هناك اعتراضات ذات طبيعة تقنيّة ترى أنّ استخدام JavaScript لوصف هيكل المُكوّن ومظهره يعني أنّنا سنخسر تحسينات الأداء الّتي يُنفّذها المُتصفّح على ملفّات CSS وHTML ومن ذلك تفسير كلّ ملفّ في مسلك (thread) منفصل مثلًا، كون JavaScript أحاديّة المسلك (single-threaded). مهما يكن الأمر، فإنّ اتّجاه تطوير الويب ماضٍ نحو فلسفة المُكوّنات؛ وحتّى من يعارض هذا الخلط من المطوّرين، فإنّهم يحتاجون لربط منطق التّطبيق بمظهره بطريقة ما، ومن ذلك استخدام لغات القوالب مثل Handlebars وMoustache، والّتي تُعيد اختراع العجلة من جديد باستخدام صيغة جديدة لحلقات for والجمل الشّرطيّة، فلماذا لا نستخدم JavaScript الّتي نألفها بكامل قوّتها بدلًا من ذلك؟
إليك مثالًا حقيقيًّا من WebCeph عن JSX، أو في الحقيقة TSX، وهي النسخة ذات الأنواع من JSX الّتي توفّرها TypeScript:
const Content = pure(({ hasImage, shouldShowLens, isLoading }: Props) => {
if (hasImage) {
return (
<div>
{
shouldShowLens ? (
<Lens className={classes.lens} margin={15}>
<CephaloImage />
</Lens>
) : null
}
<CephaloCanvas />
</div>
);
} else if (isLoading) {
return (
<div className={classes.loading_container}>
<CircularProgress color="white" size={120} />
</div>
);
}
return <CephaloDropzone />;
});
لاحظ كيف يمكننا استخدام كلّ تعابير اللّغة من مُتغيّرات وتفكيك وجمل شرطيّة، وذلك لأنّ JSX ليست إلّا JavaScript، فكلّ عبارة من مثل هذه:
<div>Some text here</div>;
ليست إلّا طريقة مُبسّطة لكتابة:
React.createElement(
"div",
null,
"Some text here"
);
وفي الحقيقة هذا هو النّصّ البرمجيّ الّذي تحصل عليه عندما تقوم بتحويل JSX إلى JavaScript باستخدام Babel. يمكنك تجربة ذلك على موقع Babel.
كيف تعمل React؟
الجزء الثّالث في React والّذي ربّما يكون سببًا مُهمّا في شعبيّـتها هو Virtual DOM، والّذي يعني أنّك باستخدامك لمكوّنات React تتجنّب التّعامل المباشر مع شجرة العناصر في الصّفحة، وتترك هذه المهمّة لـReact.
لهذا الأمر عدّة ميّزات:
- وجود طبقة افتراضيّة بين مُكوّنات مشروعك والصّفحة الحقيقيّة يسمح بإجراء عدد من تحسينات الأداء المُهمّة، فمن المعروف أن التّعامل مع DOM في المتصفّحات (DOM manipulation) بطيء مقارنة مع العمليّات الحسابيّة المُجرّدة، وهو ربّما عنق الزّجاجة (bottleneck) في أداء تطبيقات الويب اليوم.
- تعتمد React لأسلوب التّصريحي (declarative) في البرمجة، أيّ أنّك، وبدلًا من أن تأمر المتصفح برسم عنصر مُعيّن في مكان مُعيّن، تكتفي بوصف شكل المُكوّن وخصائصه، لتقوم React في الخفاء بتنفيذ الأوامر المطلوبة للوصول إلى هذا الشّكل. لهذا الأسلوب في البرمجة انعكاس مهم جدًّا على طريقة كتابة النّصّ البرمجيّ، فإذا أردت إجراء تغيير ما على خصائص عنصر أو مظهره، فإنّ لن تحتاج إلى أن تُجري هذه التّغييرات بنفسك، بل كل ما عليك فعله هو وصف شكل العنصر المرغوب في لحظة ما من سير برنامجك، أو ما يُسمّى دورة حياة المُكوّن (component lifecycle)، وستتولّى React إظهار هذا العنصر بإجراء عمليّة تفريق (diffing) بين المظهر الحاليّ للصّفحة والتغييرات الّتي طرأت على مُكوّنك، وعندها ستقوم المكتبة بإجراء أقل قدر من التّغييرات على الصّفحة للوصول إلى المظهر الجديد، دون إعادة رسم كامل الصّفحة.
- تقوم React أيضًا بجمع التّغييرات وتطبيقها على دفعات (batching) بدلًا من تنفيذ كل تغيير مباشرة على الصّفحة، الأمر الّذي يسمح لحلقة الأحداث (event loop) أن تستمرّ دون إعاقة (blocking) معظم الوقت، إلّا في الوقت الّذي يتمّ فيه رسم الإطار في الصّفحة (rendering).
Redux
Redux هي حاوية لحالة التّطبيق قابلة للتّوقّع
قلنا إنّ React تقوم بمهمّة واحدة فقط، وهي رسم عناصر الواجهة، وتترك للمُطوّرين حرّيّة اختيار الأجزاء الأخرى من تطبيقاتهم وكيفيّة الرّبط بين الواجهة والبيانات، هذا قد يكون مُربكًا لمن اعتاد على استخدام أُطر عمل تفرض عليه أسلوبًا مُعيّنًا في جلب البيانات وربطها، إلّا أنّ حرّيّة الاختيار هذه قد تكون السّبب المباشر في بقاء React مُتربّعة على عرش تطوير الويب لبضع سنين (بضع سنين في عالم تطوير الويب هي زمن طويل!)، وقد تكون أيضًا سبب رضى الأغلبيّة السّاحقة من المطوّرين عن استخدام React.
معماريّة Flux: تدفّق البيانات باتّجاه واحد (One-way data flow)
يُعرّف مُطوّرو مكتبة Redux المكتبة على أنّها «حاوية لحالة التطبيق قابلة للتّوقّع» (predictable state container)، ويبدو أنّ اختيار مصطلحات مُعقّدة لوصف فكرة بسيطة أمرٌ مُهمّ لتبدوَ ذكيًّا 😎
لكي نفهم Redux علينا أوّلًا فهم معماريّة Flux، وهي طريقة لتنظيم البيانات في تطبيقك اقترحها مُطوّرو React أنفسهم، تقوم هذه الطّريقة على جمع كلّ بيانات تطبيقك في مُستودعات (stores)، هذه المُستودعات ليست سوى كائنات JavaScript تحوي بعض الخصائص، فمثلًا لو كان لدينا تطبيق قائمة مهامّ، فربّما يكون المستودع مُشابهًا لهذا:
const store = {
todos: [
{ id: 1, text: 'Learn React', done: true },
{ id: 2, text: 'Learn Flux', done: false },
],
};
كما ترى فإنّه لا بدّ من اختيار اسم معقّد لوصف كائن بسيط! على أيّة حال، ستصل لمرحلة تتفهّم فيها الحاجة لاختيار مصطلح واضح لكلّ جزء في برنامجك، فمن المعروف أنّ تسمية الأشياء هي واحدة من أعقد المُشكلات في علوم الحاسوب!
حسنًا قد تبدو فكرة المستودعات بديهيّة، لكنّ أطر العمل مثل Angular 1 كانت تعتمد على فكرة نماذج البيانات (Data Models) الّتي تجعل البيانات تُخزّن جنبًا إلى جنب مع عناصر الواجهة المرئيّة، فلو كان لدينا مثلًا حقل إدخال لنصّ المهمّة المطلوب إنجازها في قائمة المهام، فإنّ Angular تطلب منك ربط حقل الإدخال بنموذج (ng-model) وإجراء التّغيير في هذا الحقل يؤدّي إلى إحداث تغيير في هذا النّموذج.
المشكلة تتضّح عندما يرتبط نموذج بيانات واحد بأكثر من موضع في الواجهة، وعندها فإنّ إجراء تغيير في أحد المواضع سيؤدّي إلى تغيير التّمثيل المرئيّ للمواضع الأخرى، ومع أنّ هذا هو السلوك المطلوب، إلّا أنّ ربط البيانات بالواجهة هو السّبب الأوّل والأخير لمشاكل توسعة التطبيق وصيانتها (scaling and maintainability)، إذ أنّك ستحتاج في كلّ مرّة تُجري فيها تغييرًا على طريقة عرض البيانات في تطبيقك إلى التّفكير في انعكاس ذلك على نموذج البيانات والعناصر الأخرى، ولهذا بدأ المُطوّرون يُدركون أنّ فكرة ربط البيانات ثنائيّ الاتجاه (two-way data-binding) كما يُسمى، ليس فكرة جيّدةً!
على العكس من ذلك تُقدّم معماريّة Flux فكرة مُختلفة لتنظيم البيانات في تطبيقك وعكسها في الواجهات، فإذا افترضنا أنّ البيانات مُخزّنة في مُستودع، وأنّنا بحاجة لعرض هذه البيانات في الصّفحة، فإنّنا ننسخ الجزء الّذي تحتاجه المُكوّنات من البيانات من المُستودع ثمّ نقوم بتعديل شكل هذه النّسخة بحيث تُلائم احتياجات هذا المُكوّن.
لنأخذ صفحة Facebook كمثال: تتكوّن الصّفحة من شريط علويّ يتضمّن اسم المستخدم وصورته، وشريط جانبيّ يتضمّن أيضًا اسم المستخدم وصورته، بالإضافة إلى قائمة الاصدقاء على جانب الصّفحة وصندوق الدّردشة في الأسفل.

واجهة Facebook
يمكننا تنظيم هذه المعلومات في مستودعات، ثمّ ربط المكوّنات بالمستودعات الّتي تحتاجها، فمثلًا يحتاج الشّريطان العلويّ والجانبيّ إلى بيانات من مستودع بيانات المستخدم، وأمّا قائمة الأصدقاء فهي تحتاج إلى مستودع قائمة الأصدقاء لعرض بعض الأصدقاء الّذين تواصلت معهم مؤخّرًا، وتحتاج أيضًا إلى قائمة بالأصدقاء المُتّصلين لعرض مؤشّر الحالة قرب الاسم (النقطة الخضراء)، وأمّا صندوق الدّردشة فهو يحتاج إلى أسماء الأصدقاء، وحالة اتّصالهم، وكذلك للرّسائل من مستودع الرّسائل.

معماريّة Flux
فمثلًا، لنفترض أنّك أغلقت صندوق الدّردشة، لكنّ صديقك أرسل لك رسالة بعد ذلك، بالطّبع يجب على Facebook أن يُظهر إشعارًا في الشّريط العلويّ بوجود رسالة غير مقروءة، وعندما تقرأ الرّسالة، فيجب أن يختفي هذا الإشعار، وفي الحقيقة فإنّ بإمكانك قراءة الرّسالة بإعادة فتح صندوق الدّردشة أو الانتقال إلى الإشعار في الشّريط العلويّ والنّقر عليه، ويجب في كلا الحالتين أن تبقى الواجهة منسجمة (consistent)، أي أن قراءة الرّسالة من أي مكان يجب أن ينعكس في كلّ المواضع الّتي تعتمد على مستودع الرّسائل.
في معماريّة Flux، لا يُسمح للمُكوّنات المرئيّة أن تقوم بتعديل البيانات في المستودع مباشرةً، ولو فعلنا ذلك لعدنا إلى مشكلة ربط البيانات ثنائي الاتّجاه (two-way data-binding)، وعندها يجب أن يعلم كلّ مكوّن يستخدم مستودع الرّسائل بوجود المكوّنات الأخرى، لتبقى الواجهة في أيّ لحظة منسجمة. بدلًا من ذلك تتبنّى معماريّة Flux أسلوبًا مختلفًا لتعديل البيانات، إذ أنّ المكوّن الّذي يريد تعديل البيانات يقوم بوصف التّغيير المطلوب إجراؤه ثمّ يُرسِل (dispatch) هذا الوصف (الّذي يُسمّى حدثًا Action) إلى المُستودع، الّذي يقوم بدوره بإنجاز هذه التّغييرات بالطّريقة الّتي يراها مُناسبة، لتعود البيانات بعد تعديلها «وتنساب» إلى المُكوّنات المرئيّة، ومن هنا جاء اسم Flux، وبهذا تكون كلّ المُكوّنات المرئيّة منسجمة في أيّ لحظة من الزّمن، لأنّها تستقي بياناتها من مستودع أعلى منها.

تعديل البيانات في معماريّة Flux
بالطّبع بإمكان الشّريط العلويّ أن يُرسل الحدث نفسه، ولن يتغيّر شيء، وهذا هو سبب الانسجام في الواجهة:
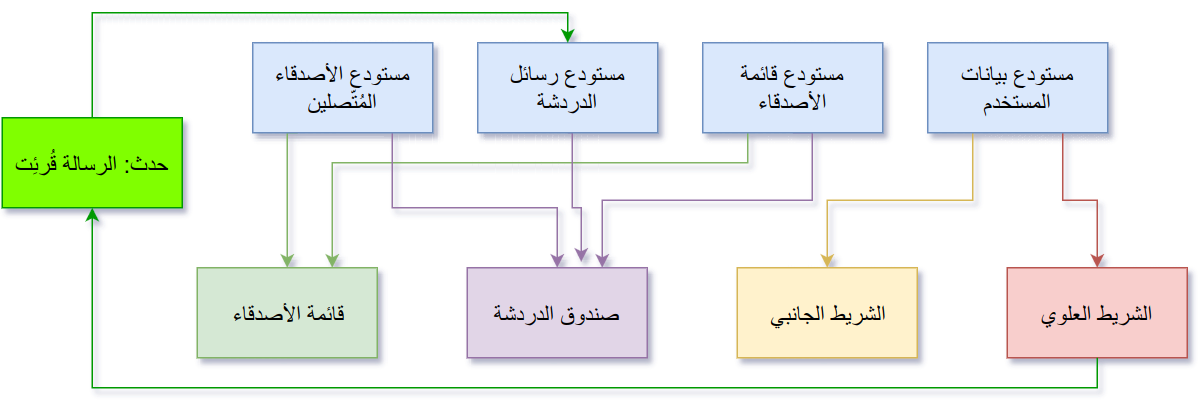
تعديل البيانات في معماريّة Flux
من الواضح أنّ معماريّة Flux مُلائمة جدًّا لتطبيقات React على الرّغم من أنّ أيًّا منهما ليس محصورًا بالآخر كما قلنا، لكنّهما يتكاملان بشكل رائع، ففصل الاهتمامات يعني أنّ المُكوّنات ليست بحاجة لمعرفة طريقة تنظيم البيانات في المستودع، بل إنّها تستقي هذه البيانات من المستودع بعد تعديلها بشكل يناسب احتياجاتها، كما أنّها لا تحتاج لمعرفة شكل البيانات في المستودع إذا أرادت إجراء تغيير ما على البيانات، بل يكفي أن تصف شكل التّغيير المطلوب، وبعد إجراء هذه التّغييرات وانسيابها مُجدّدًا فإنّ React تتدخّل لتقوم باستنتاج أقل قدر مطلوب من التّغييرات على الصّفحة للوصول إلى المظهر الجديد للمُكوّن (diffing).
من المهمّ أيضًا أن نُدرِك أنّ الأحداث ليست مرتبطة بالضّرورة بالمكوّنات، فيمكن أن تأتي الأحداث من الشّبكة أو أيّ مصدر آخر، والمهمّ أن «تصبّ» في مستودع البيانات، وتعود فتنساب للمكوّنات المرئيّة:
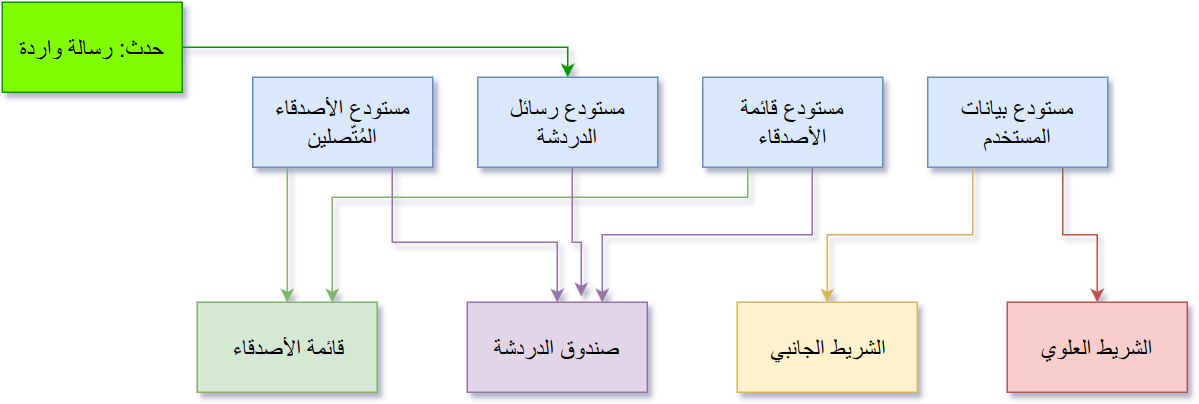
تعديل البيانات في معماريّة Flux
هذا هو بالضّبط السّبب الّذي جعلني أختار React ومعماريّة Flux لبناء WebCeph، فهو تطبيق يحتوي كمًّا ضخمًا من البيانات، وانسجام الواجهة يسمح لي بتطوير المُكوّنات المختلفة من الواجهة كلّ منها على حدة، ويسمح لي بإزالة أو إضافة مكوّنات في أي وقت دون خوفٍ من أن يؤثّر ذلك على عمل التّطبيق.
المُكوّنات الغبيّة (Dumb components)
قد يكون من المغري عند العمل على تطبيق ويب أن يقوم كلّ مكوّن بإدارة البيانات الخاصّة به وتعديلها، فمثلًا، عند النّقر على الصّورة في WebCeph لرسم نقطة، قد يخطر لك في البداية أنّ مكوّن الصّورة يقوم بتلقّي حدث النّقر بالفأرة ثمّ رسم النّقطة في الموضع الموافق على الصّورة:
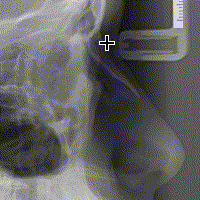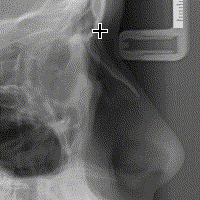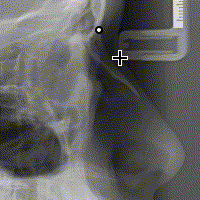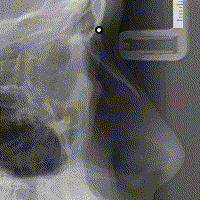
هذا هو السّلوك البديهيّ والأكثر سهولة، لكنّ Flux تجعلك تعيد ترتيب أولويّاتك عند هندسة المشروع، وتطلب منك ألّا يكون هدفك الأوّل هو «البديهيّ» ولا «السّهل»، بل أن تكون البساطة هي الاعتبار الأوّل، وستكتشف مع ازدياد خبرتك في Flux أنّ ترك المُكوّنات تُعدّل البيانات الّتي تعرضها ليس الحلّ الأكثر «بساطة»، فكلّ التّعقيد في البرنامج هو ارتباط المُكوّنات بالبيانات كما قلنا. إليك ما يحدث عند النّقر على الصّورة في WebCeph:

لاحظ كيف أنّ الأسهم تُشير باتّجاه واحد (تدفّق البيانات باتّجاه واحد)
يُرسل حدث (action) النّقر على الصّورة مع إحداثيّات الفأرة بالنّسبة للصّورة عبر مُرسل الأحداث (dispatcher) إلى مستودع البيانات، الّذي يقوم بدوره بالاحتفاظ بهذه الإحداثيّات، لتقوم React بعكس هذه التّغيّرات في الواجهة، والّتي تؤدّي إلى إظهار النّقطة في الموضع المناسب.
وجود البيانات في المستودع يجعل إمكانيّة الاستفادة منها غير محصورة بالمكوّن المسؤول عن رسم النّقاط، فبناء على هذه النّقاط نستطيع معرفة الخطوة التّالية في التّحليل، ويمكننا حساب الزّوايا ورسم الخطوط المعتمدة على هذه النّقطة، عبر الوصول إليها من المستودع، بدلًا من أن يحتاج حساب الزّوايا إلى الاعتماد على المُكوّن المسؤول عن رسم النّقاط.
تذكّر: البديهيّ ليس دومًا بسيطًا، والبسيط ليس دومًا سهلًا.
لاحظ إذًا أنّ المُكوّنات في معماريّة Flux تصبح مجرّد «طريقة لعرض البيانات»، وهي بذاتها لا تقوم بتعديل البيانات، ولا يهمّها على الإطلاق من أين تأتي هذه البيانات ومن يحتاجها، كل ما تفعله هذه المكوّنات هي أن تتلقّى مجموعة من الخصائص وتعرضها بشكل أو بآخر، فهي إذًا مكوّنات «غبيّة» (dumb components). هذا الفصل يسمح لنا باختبار كلّ جزء من تطبيقنا على حدة، فلو احتجنا إلى اختبار سلوك مكوّن رسم الصّور، فكلّ ما علينا هو إعطائه مجموعة من الخصائص الّتي تصف مواضع النّقاط على الصّورة، ثمّ نتأكّد من كونه قد قام برسمها، ولسنا بحاجة لإنشاء مستودع للبيانات، أو حتّى للنقر على الفأرة، بل يمكننا تجربة المُكوّن في Node.js دون تشغيل المتصفح! وهذا يسهّل بشكل كبير من اختبار الوحدات (unit tests).
كيف تعمل Redux؟
لعلّك لاحظت أنّ الأفكار الّتي ذكرناها حتّى الآن تفرض عليك شروطًا مُعيّنة في طريقة كتابة مُكوّنات وتنظيم البيانات في تطبيقك، وتُملي عليك كيف يجب أن تُجري التّعديلات، والحقيقة أنّ قوّة Redux ليست في الحرّيّة التّي تمنحك إياها، بل على العكس، فإنّه قوّتها تكمن في كونها تفرض عليك مزيدًا من الشّروط في إنشاء تطبيقك، حتّى تصل لقناعة مُفادها أنّه كلّما زادت القيود (constraints) الّتي تفرضها على نفسك في هيكلة التّطبيق (architecture) فإنّك تصبح مُطوّرًا أفضل وأكثر كفاءة وسرعة، وذلك بشرط أن تكون هذه القيود ملائمة لمشروعك.
بصراحة فإنّ Redux لم تُغيّر فقط من طريقة تفكيري في كتابة التّطبيقات، بل غيّرت من نظرتي للبرمجة بالكامل، وجعلتني أؤمن بمنهج مُحدَّد جدًّا في طريقة هندسة تطبيقاتي، وقد أصبحت مُقتنعًا بأنّ البرمجة التّابعيّة (functional programming) هي الطّريقة الوحيدة لبناء المشاريع الضّخمة مع الحفاظ على سلامة عقلي، وقد بتُّ أُكنّ احترامًا كبيرًا للجانب النّظريّ من علوم الحاسوب وأدرك تمامًا أن فكرة «لكي تتعلّم البرمجة، عليك أن تتعلّم الرّياضيّات» هي فكرة صحيحةً تمامًا، لكنّ ليس على المستوى السّطحيّ الّذي يظنّه معظم المبتدئين، بل على مستوىً أعمق من ذلك بكثير. سأوضّح ما أقصده وأستعرض مفهوم البرمجة التّابعيّة بعد قليل.
تتبنّى Redux معماريّة Flux من حيث وجود مستودعات (Stores) للبيانات ومن حيث استخدام الأحداث (Actions) الّتي تُرسل إلى المستودع، لكنّها أيضًا تفرض قيودًا أخرى:
- يجب أن تكون كل بيانات تطبيقك في مستودع واحد فقط.
- في كلّ مرّة تُريد فيها تعديل البيانات في المستودع، يجب أن تُنشئ نسخة جديدة من كامل البيانات في المستودع.
قد تبدو هذه القيود للوهلة الأولى غير منطقيّة، لكنّك بعد إتقان Redux ستدرك العبقريّة الكامنة وراءها، فأمّا مبرّر وجود كامل البيانات في مستودع واحد، فهو أنّ ذلك يجعلها أسهل إدارة، بل ويسمح بتنفيذ أفكار لم نكن لنتصوّرها من قبل، ومن ذلك أدوات مطوّري Redux الّتي تسمح لك بالتّنقّل في مسير العمليّات في تطبيقك كما لو كنت تشاهد مقطع فيديو! هذا الحديث يقودنا إلى فكرة التّوابع النّقيّة الّتي سأوضّحها بعد قليل، ولكنّ تخيّل أن تطبيقك هو تابع رياضيّ يأخذ البيانات ويُعيد تمثيلًا مرئيًّا موافقًا لهذه البيانات:
وجود البيانات في مكان واحد يجعل تحقيق هذه الفكرة سهلًا للغاية، وهي أيضًا تعتمد على القيد الثّاني الّذي تفرضه Redux، والّذي يفرض إنشاء نسخة من البيانات كاملةً في كلّ مرّة تُريد تعديل أي جزء منها، كما قلنا فإنّ تطبيقك هو تابع رياضي للبيانات، وكما في التّابع الرّياضي التّالي:
فإن تّعويض قيم مختلفة لـx يُعطي نتيجة مختلفة في كلّ مرة، وكذلك فإنّ تعويض بيانات مختلفة في تطبيقك يُعطي تمثيلًا مرئيًّا في الصّفحة مُختلفًا في كلّ مرّة:
const App = (data) => <View {...data} />;
App(data1) = View1;
App(data2) = View2;
سأوضّح الفكرة بمثال، لنقل إن التّمثيل المرئيّ لتطبيقك هو صفحة تعرض اسم المستخدم كاملًا، يمكن كتابة ذلك في JSX كما يلي:
const App = ({ user }) => (
<div>
{`${user.firstName} ${user.lastName}`}
</div>
);
فإذا كان لدينا البيانات التّالية المُخزّنة في المستودع:
const store = {
user: {
firstName: 'Fawwaz',
lastName: 'Orabi'
}
};
فإنّ تعويضها في التّطبيق يُعطينا صفحة تعرض اسم هذا المُستخدم، وبالطّبع فإنّ تعويض بيانات مستخدم آخر يُعطينا صفحة تعرض اسم مستخدم آخر.
See the Pen yVypvw by Muhammad Fawwaz Orabi (@fwz) on CodePen.
مستودع البيانات هو أيضًا تابع رياضيّ!
نعلم حتّى الآن أنّ مكوّنات معماريّة Flux هي:
- مستودع البيانات (store)
- الأحداث (actions)
- مُرسل الأحداث (dispatcher)
قلنا أيضًا إن المكوّنات المرئيّة هي تمثيل للبيانات، وأنّ تعديل البيانات يتمّ من خلال إرسال الأحداث، والّذي يؤدّي إلى تعديل البيانات في المستودع، ممّا يؤدّي إلى تغيير التّمثيل المرئيّ لهذه البيانات، أي ما يراه المُستخدم.
لو فكرنا بمنهجيّة منطقيّة، فإنّنا نستطيع أن نقول أنّ بيانات تطبيقنا في أي لحظة هي حالة ناتجة عن تعديل البيانات في اللّحظة السّابقة من خلال الأحداث، أي أنّ تأثير الحدث على البيانات يؤدّي إلى إنتاج بيانات جديدة.
تأخذ Redux هذه الفكرة، وتقترح أنّ ننظر إلى مستودع البيانات على أنّه تابع رياضيّ، مُعاملاته هي الحالة السّابقة والحدث المُرسَل، وقيمته هي الحالة الجديدة.
ما الّذي قلته بخصوص الرّياضيات؟ إنّها الرّياضيات في كلّ مكان! 😄
هذه الفكرة العبقريّة، على بساطتها، تصلح لبناء أيّ تطبيق مهما بلغ تعقيده، فكلّ تطبيق، مهما كان الغرض منه (دردشة، ترسيم صورة)، لا بدّ أن يحتاج لعرض بيانات (الرسائل، النقاط والخطوط)، ولا بدّ أن يوفّر طريقة لتعديلها (إرسال رسالة وعرضها، إضافة نقطة وعرضها). لا عجب أن Redux جذبت اهتمام معظم المُطوّرين المستطلعة آراؤهم لهذا العام!
في علوم الحاسوب، يُسمّى التّابع الّذي يتلقّى قيمةً أو أكثر ويُعيد قيمة وحيدة بتابع الاختزال (reducer function)، ومن هنا أتت تسمية Redux.
يمكن تمثيل تابع الاختزال في التّطبيق بهذه الطّريقة:
const reducer = (previousState, action) => {
// Perform work here...
return newState;
};
ولو أمعنت التّفكير، لاستنتجت أنّ منطق التّطبيق كلّه يكمن في هذا التّابع، فأي تطبيق يمكن تمثيله بهذا الأسلوب كما قلنا، وكلّ ما يفعله التّطبيق هو الاستجابة للأحداث لإنتاج بيانات جديدة من البيانات السّابقة، فـRedux إذًا هي الجزء المسؤول عن كيفيّة عمل التّطبيق، وأمّا React فهي المسؤولة عن كيفيّة عرض التّطبيق.
البيانات المُشتقّة (Derived data)
لنعد إلى مثال صفحة Facebook، تذكر أنّنا قلنا إن الشّريط العلويّ وصندوق الدّردشة كلاهما يتعمدان على مستودع الرّسائل، ولنبدأ بالشّريط العلويّ الّذي يعرض عدد الرّسائل غير المقروءة.
قد يخطر لك عندما تبدأ العمل بمعماريّة Flux أن تُخزّن عدد الرّسائل المقروءة جنبًا إلى جنب مع المستودع:
{
unreadCount: 1,
out: [
{
id: 'message_1037526',
from: 'me',
to: 'friend_1',
text: 'Writing about Flux!'
},
]
in: [
{
id: 'message_1245325',
from: 'friend_1',
to: 'me',
text: 'What are you doing?',
read: true,
},
{
id: 'message_1037526',
from: 'friend_2',
to: 'me',
text: 'Hello!',
read: false,
},
],
}
لكنّ هذا مخالف لمبدأ مُهمّ في علوم الحاسوب، وهو مصدر واحد للحقيقة (Single source of truth)، ما الّذي يحدث لو قمت بإضافة رسالة جديدة إلى مصفوفة الرّسائل، ونسيت تحديث عدد الرّسائل غير المقروءة؟ أو على العكس، ماذا لو قُرئت رسالة ونسيت إنقاص عدد الرّسائل المقروءة؟ سيؤدّي ذلك إلى عدم انسجام الواجهة، فالشّريط العلويّ سيُظهر وجود رسالة غير مقروءة، وأمّا عند الانتقال إلى صفحة الرّسائل فسيُفاجَأ المستخدم بعدم وجود رسالة.
ليس ذلك فحسب، بل ماذا لو أردت عرض الرّسائل غير المقروءة جانب اسم الصّديق في صفحة الرّسائل؟ هل يعني هذا أنّك ستحتاج إلى إضافة مُدخل جديد في المستودع لكلّ صديق؟ وعندها ستحتاج لتعديل عدد الرّسائل غير المقروءة لصديق ما، وكذلك عدد الرّسائل غير المقروءة الإجمالي، أعتقد أنّك بدأ تُدرك صعوبة التّعامل مع هذا النّوع من البيانات.
عندما تُصادفك مشكلة كهذه، عليك أن تُعيد التّفكير في هيكل مستودع البيانات، فالحقيقة أنّ الشّريط العلويّ وصندوق الدّردشة كلاهما مظهران مختلفان لشيء واحد، هو الرّسائل نفسها.
الهيكل المُناسب للتّعبير عن هذه البيانات قد يكون كما يلي:
{
messages: [
{
id: 'message_1245325',
from: 'friend_1',
to: 'me',
text: 'What are you doing?',
read: true,
},
{
id: 'message_1037526',
from: 'friend_2',
to: 'me',
text: 'Hello!',
read: false,
},
{
id: 'message_1037526',
from: 'me',
to: 'friend_1',
text: 'Writing about Flux!'
},
],
}
كما ترى فإنّ الرّسائل مخزّنة بصورة مصفوفة تحتوي كلّ الرّسائل سواء الصّادرة أو الواردة وبغض النّظر عمّن أرسلها، وقد استغنينا عن عدد الرّسائل، الكيفيّة الّتي نمثّل بها البيانات في المستودع قد تختلف بحسب اعتبارات الأداء أو حاجة تطبيقك، لكن ما يهمّنا الآن هو أنّنا بحاجة لعرض عدد الرّسائل في الشّريط العلويّ، وهذا يعني كما قلنا سابقًا، أنّنا بحاجة لتعديل الرّسائل بصورة ما قبل أن تصل إلى المكوّن الّذي يحتاجها. تُسمّى عمليّة تعديل البيانات بالاشتقاق، وفي هذه الحالة فإنّ عدد الرّسائل غير المقروءة هو بيانات مشتقّة (derived data)، وبما أنّ مستودع البيانات هو مجرّد كائن JavaScript، فإنّ بإمكاننا استخدام مكتبة مثل lodash لتصفية الرّسائل غير المقروءة وعدّها:
import _ from 'lodash';
const getUnreadMessageCount = (state) => {
return _.countBy(state.messages, 'read').false;
};
وأمّا بالنّسبة لصندوق الدّردشة، فإنّنا بحاجة للرّسائل الصّادرة إلى صديق مُعيّن أو الواردة منه، بغض النّظر عمّا إذا قُرئت أو لا:
const getMessagesForFriend = (state, friendId) => {
return _.filter(
state.messages,
message => (
message.to === friendId ||
message.from === friendId
),
);
};
لاحظ أنّ بإمكاننا الآن توليد شكل البيانات الّتي يحتاجها أيّ مكوّن قد نُضيفه إلى تطبيقنا لاحقًا، فشكل المستودع يجب ألّا يكون مُرتبطًا بالمكوّنات الحاليّة، يمكنك النّظر إلى مستودع بياناتك على أنّه قاعدة بيانات، وأمّا التّوابع الّتي تشتقّ البيانات فهي كعبارات الاستعلام في SQL، الّتي قد تعطيك عدد الرّسائل أو تصفّيها بحسب المُرسل أو المُستقبل، ومن المعلوم أنّ قاعدة البيانات يجب أن تحتوي المعلومات الأساسيّة فقط دون المعلومات المُشتقّة. أنصحك بشدّة بقراءة المقال 10 Tips for Better Redux Architecture لـEric Elliott.
قد تتساءل عن انعكاسات الاشتقاق على أداء التّطبيق، وقد تُبرّر حاجتك لتخزين البيانات المُشتقّة في المستودع بكون ذلك يتطلّب عمليّات حسابيّة أقلّ، ففي كلّ مرة تريد فيها عرض عدد الرّسائل، فإنّك تستدعي تابع الاشتقاق الّذي يُعيد تنفيذ عمليّة البحث عن الرّسائل غير المقروءة ضمن المستودع، ولفهم كيف يمكن تجنّب هذه الحسابات المُتكرّرة، علينا أوّلًا فهم معنى «التّوابع النّقيّة».
البرمجة التّابعيّة (Functional programming) والتّوابع النّقيّة (Pure functions) – أو كما تُسمّى، الرّياضيّات!
لنُعد إلى التّابع الرّياضيّ السّابق ذاته:
كما نعلم، فإنّ تعويض قيم مُختلفة في تابع رياضيّ قد يُعطي نتائج مختلفة:
وأمّا تعويض القيمة نفسها، فهو يعطي دومًا القيمة نفسها.
ماذا لو قلت لك إنّ لديّ تابعًا آخر، g(x)، يعطيني قيمة مختلفة في كلّ مرّة أعوّض فيه x = 5، بالطّبع قد تتهمني بالجنون، لكن للأسف، هذا هو واقع JavaScript ومعظم لغات البرمجة المُستخدمة اليوم.
افترض أنّ لديّ التّابع التّالي الّذي يُغيّر لون نص الصّفحة:
var content = document.getElementById('content');
function setTextColor(color) {
content.style.color = color;
}
setTextColor('red');
افترض أنّني في موضع آخر من الصّفحة، قمت بإنشاء مُتغيّر آخر باسم مُطابق سهوًا، لكنّه يُشير إلى محتوى المقالة:
var content = document.querySelector('.article-text');
فإنّ استدعاء التّابع setTextColor هذه المرّة سيُغيّر لون نصّ المقالة بدل لون الصّفحة، وهذا يعني أنّنا لا نستطيع ضمان أنّ التّابع سيُحدث نفس التأثير في كلّ مرّة نستدعيه، حتّى وإن كانت مدخلاته هي نفسها.
للأسف فإنّ JavaScript تجعل هذا الخطأ يسيرًا، بسبب إمكانيّة وجود الوصول إلى المُتغيّرات في النّطاق العام (global scope) وتساهل اللّغة في إعادة فرض المُتغيّرات.
ما الحلّ لهذه المشكلة إذًا؟
المشكلة تكمن في كون التّابع يستطيع الوصول إلى المُتغيّر content الّذي يقع خارجه، وهذا يعني أنّ التّابع «يعلم» بوجود مُتغيّر، مع أنّنا لم نُعلمه بوجوده، تخيّل لو كان التّابع g(x) مكتوبًا بهذه الطّريقة:
أعتقد أنّ المشكلة تكون أكثر وضوحًا عندما ننظر إلى التّابع على أنّه تابع رياضيّ، فحتّى لو لم يكن لديك علم بالبرمجة، تستطيع بسهولة أن تقول أنّ هذا التّابع ليس صحيحًا، لأنّ y ليست معلومة، والصّحيح أن يُكتب هكذا:
أيّ التّابع الرّياضيّ يتلقّى كلّ المعلومات الّتي يحتاجها لإجراء العمليّة الحسابيّة ضمن معاملاته، وهذا يعني أنّنا نستطيع الآن أن نضمن أنّ استدعاءه أيّ عدد من المرّات بنفس القيم لـx وy سيُعطينا النّتيجة نفسها كلّ مرّة.
إذًا فالبرمجة التّابعيّة تقوم على فكرة بسيطة: «يجب أن تكون توابعك في البرمجة توابع رياضيّة صحيحة»، وهذا يعني:
- يجب أن يتلقّى التّابع كلّ ما يلزمه من معلومات ضمن مُعاملاته
- يجب ألّا يعلم التّابع بوجود شيء خارج حدوده، ولا يحاول الوصول إلى ما هو خارج حدوده
إذًا كيف نجعل التّابع setTextColor تابعًا نقيًّا؟ ببساطة، اجعل content واحدًا من معاملاته:
function setTextColor(content, color) {
content.style.color = color;
}
وهكذا فإنّ content ضمن التّابع تعني content المُعامل، وليس المُتغيّر المفروض خارج التّابع. وبدلًا من استدعائه باللّون المرغوب فقط، فإنّنا نمرّر العنصر المطلوب تغيير لونه أيضًا:
setTextColor(document.getElementById('content'), 'red');
وهكذا يُصبح التّابع «نقيًّا» (pure function) أيّ أنّه تابع لا يصل لخارج حدوده، ويمكن تمثيله بشكل رياضيّ سليم.
ولكن ما الفائدة العمليّة لجعل التّابع نقيًّا؟
لاحظ أنّ
setTextColorأصبح قابلًا للاستخدام على أكثر من عنصر، وليس مُقيّدًا بتغيير لون الصّفحة فقط، والحقيقة أنّه من الأفضل إعادة تسمية المُعامل الأوّل:function setTextColor(el, color) { el.style.color = color; }وهكذا أصبح تابعًا عامًّا يصلح لإعادة الاستخدام في أكثر من موضع
يمكن أيضًا أن نتحقّق بسهولة من كون التّابع يؤدّي المهمّة المطلوبة، بمجرّد أن نُمرّر له كائنًا يطابق شكله شكل عناصر الصّفحة ولونًا، ودون الحاجة لمحاكاة كامل بيئة المتصفّح.
var mockElement = { style: { color: 'blue', } }; setTextColor(mockElement, 'red'); expect(mockElement.style.color).toBe('red');تذكّر أنّ التّوابع الرّياضيّة (النّقيّة) تُعيد دومًا نفس النّتيجة عند إعطائها نفس المُعاملات، وهذا يعني أنّ بإمكاننا حفظ نتيجة الحساب (الّذي قد يستغرق وقتًا طويلًا) عند إجراءه أوّل مرّة:
f(5) = 2(5) + 1 = 11وبدلًا من إعادة استدعاء التّابع ثانيةً، يمكننا البحث عن وجود نتيجة f(5) في الذّاكرة واستعادتها؛ فنحن نعلم أنّه طالما كانت القيم الّتي يتلقّاها التّابع في كلّ مرة متماثلة، فإنّ النّتيجة ستكون دومًا متماثلة، ولا حاجة لتكرار الحساب. هذه هي الفكرة الّتي تقوم عليها مكتبة Reselect، الّتي أستخدمها في WebCeph بكثافة لتجنّب تكرار اشتقاق البيانات. الأمر إذًا هو موازنة بين استخدام جزء أكبر من الذّاكرة لتخزين النّتائج من جهة، أو إعادة إجراء العمليّة الّتي يؤدّيها التّابع من جهة أخرى، والخيار متروك للمطوّر بحسب ما يراه مناسبًا، فإن كانت العمليّة مُعقّدة وتستغرق وقتًا، وكانت تُستدعى كثيرًا، فقد يكون من المناسب تخزين القيمة في الذّاكرة.
أنصحك بشدّة بقراءة المقال Making your JavaScript Pure على موقع A List Apart، الّذي يشرح مشاكل التّوابع غير النّقيّة وفوائد التّوابع النّقيّة.
تذكّر إذًا أنّ البرمجة التّابعيّة ليست سوى تطبيق مبادئ الرّياضيّات، وهي متوافقة تمامًا مع المنطق والتّفكير السّليم.

واجهة التّطبيق
لا أخفي عنكم سرًّا: أنا لست من مُحبّي CSS، لا يعني هذا أنّني لا أستطيع استخدامها، بل على العكس، أُجيد التّعامل مع بعض أعقد أجزائها، لكنّني في كلّ مرّة أكتب CSS، أشعر بهذا بالضّبط:

شعوري عندما أستخدم CSS
الواجهة الحاليّة للتّطبيق تستخدم Flexbox بكثافة، وهو بالفعل طريقة تُعطيك مرونة كبيرة (pun intended) في وصف الواجهة، لكنّه استخدامه مرتبط بعشرات المُشكلات في التّوافق بين المُتصفّحات، والحقيقة أنّ الواجهة ربّما لا تعمل حاليًّا على Edge (لم أقم بالتّجربة بعد).
بعض هذه المشاكل يُحل باستخدام Autoprefixer، وقد استخدمته، ولكنّ بعضها نابع من طريقة تفسير المتصفّحات المختلفة للمعيار، وللأسف فإنّ هذا يمنع الاعتماد الكامل عليه بين مطوّري الويب، مع أنّه مدعوم في معظم المتصفّحات (على الورق كما يقولون).
مشكلة CSS مع تطبيقات الويب، أنّها صُمّمت في وقت كان الاستخدام الوحيد للويب هو عرض «الصّفحات»، الّتي كانت مقالات أو مستندات رسميّة أو غيرها، وأمّا استخدام الويب لبناء «تطبيقات» فقد برزت معه العديد من التّحديات الّتي لم تكن في الحسبان، لحسن الحظّ تحسّن الوضع كثيرًا في السّنوات الأخيرة، والحقيقة أنّ هناك معيارًا قادمًا يُسمّى CSS Grids، سيجعل تصميم الواجهات المُعقّدة أمرًا يسيرًا دون الحاجة لهذا الشّعور:

يمكنك ملاحظة إنّني أكره CSS جدًّا
مشكلة أخرى مع CSS، وهي تعارضها التّام مع فكرة «المكوّنات المعزولة»، في CSS كلّ مكوّن في الصّفحة سيرث عن أبيه عشرات الخصائص الّتي لم تُحدّد عليه، وإنّما حدّدت على العنصر الّذي يحتويه أو العنصر الّذي يحتوي العنصر الّذي يحتويه… إلخ. هذا متعارض تمامًا مع فكرة أنّ المكوّن معزول عمّا حوله، ويجعل المكوّنات عرضة لكثير من مشكلات العرض الّتي يصعب تتبّع سببها. لحسن الحظّ لست الوحيد الّذي توصّل لهذا الاستنتاج، فقد ظهرت فكرة CSS Modules الّتي تهدف إلى حلّ هذه المشكلة، وقد استخدمتها في التّطبيق.
إلّا أنّ مشكلة أخرى لم تحلّ مع CSS Modules، وهي التّصميم المُستجيب (responsive design)، فربّما يعلم القارئ أنّنا نستطيع تغيير مظهر الصّفحة بالاعتماد على أبعاد الجهاز أو النّافذة أو الشّاشة باستخدام media queries، وهي ميزة رائعة أتاحت تصميم مواقع مناسبة للهواتف الذّكيّة والأجهزة اللّوحيّة وغيرها، لكنّها تُكرّر خطأ CSS الأصليّ، وهو غياب عزل المكوّنات، فلو فكّرنا قليلًا في طريقة تصميمنا للمواقع المُستجيبة، للاحظنا على الفور أنّ قياس الشّاشة قد يؤثّر على طريقة عرض العنصر، وهذا يعني أنّ العنصر غير معزول، وهناك شيء خارجيّ يؤثّر عليه دون أن يعلم، ولهذا ظهر اقتراح جديد يُسمّى container queries والحقيقة أنّ هناك تطبيقًا للفكرة مُصمّم للمُكوّنات المكتوبة بـReact، لكنّها تستخدم JavaScript بالطّبع في غياب دعم المتصفّحات، وهذا ما منعني من استخدامها حاليًّا، فقد يكون لهذا أثر كبير على الأداء.
لو كنت قرأت فقرة التّوابع النّقيّة، فلعلّك لاحظت أنّنا نسعى لتطبيق المبدأ نفسه في CSS بجعلها معزولة وتتلقّى كلّ المعلومات الّتي تحتاجها، بما في ذلك الأبعاد الّتي تحويها، وهذا يعني أنّنا أقحمنا الرّياضيّات حتّى في CSS! فالمكوّنات إذًا يجب أن تكون توابع نقيّة تأخذ البيانات وتعرضها بطريقة ما، هل لاحظت كيف أنّ كلّ هذه المفاهيم مرتبطة مع بعضها، أو لنقل إنّها طرق مختلفة للنّظر في مفهوم واحد.
اعتبارات الأداء – هل يستطيع المتصفّح تحمّل كلّ هذا؟
يعرض التّطبيق الخطوات اللّازمة لإنجاز التّحليل السّيفالومتريّ الّذي يختاره المُستخدم:
الطريقة الّتي توصف فيها التّحاليل السيفالومتريّة داخليًّا هي بتركيب الزّوايا والخطوط من أبسط مكوّناتها، فمثلًا الزّاوية SNA هي الزّاوية المُتشكّلة بين الخطّين SN وNA، وكلّ من الخطّين مُكوّن من نقطتين كما هو واضح.
/**
* Midpoint of sella turcica
*/
export const S = point('S', 'Sella');
/**
* Most anterior point on frontonasal suture
*/
export const N = point('N', 'Nasion');
export const Na = N;
/**
* Most concave point of anterior maxilla
*/
export const A = point('A', 'Subspinale');
/**
* Creates an object conforming to the Angle interface based on 2 lines
*/
export function angleBetweenLines(
lineA: CephaloLine, lineB: CephaloLine,
name?: string, symbol?: string,
unit: AngularUnit = 'degree'
): CephaloAngle {
return {
type: 'angle',
symbol: symbol || getSymbolForAngle(lineA, lineB),
unit,
name,
components: [lineA, lineB],
};
};
/**
* Creates an object conforming to the Angle interface based on 3 points
*/
export function angleBetweenPoints(
A: CephaloPoint, B: CephaloPoint, C: CephaloPoint,
name?: string,
unit: AngularUnit = 'degree'
): CephaloAngle {
return angleBetweenLines(line(B, A), line(B, C), name, undefined, unit);
}
/**
* SNA (sella, nasion, A point) indicates whether or not the maxilla is normal, prognathic, or retrognathic.
*/
export const SNA = angleBetweenPoints(S, N, A);
وأمّا التّحليل السيفالومتري فهو يوصف على أنّه مجموعة من المُكوّنات، والمكوّن قد يكون زاوية أو مسافة أو غير ذلك:
type AnalysisComponent = {
landmark: CephaloLandmark;
norm: number;
stdDev?: number;
};
interface Analysis {
id: string;
components: AnalysisComponent[];
/** Given a map of the evaluated values of this analysis components,
* this function should return an array of interpreted results.
* For example, given a computed value of 7 for angle ANB,
* the returned value should have a result of type CLASS_II_SKELETAL_PATTERN
*/
interpret(values: { [id: string]: EvaluatedValue }): AnalysisInterpretation[];
}
ما يقوم به التّطبيق هو عرض الخطوات اللّازمة للوصول إلى مكوّنات التّحليل، وذلك بأخذ كلّ مكوّن، وإعادة تفكيكه إلى مكوّنات أبسط، حتّى نتوقّف عند النّقاط، الّتي تُعتبر أبسط المّكوّنات، فمثلًا، الخطوات اللّازمة للوصول إلى قيمة الزّاوية SNA هي:
- رسم النّقطة S
- رسم النّقطة N
- رسم الخطّ SN
- رسم النّقطة A
- رسم الخطّ NA
- حساب الزّاوية المُتشكّلة بين الشُّعاعين SN وNA، وهي الزّاوية SNA
فيما يلي التّابع المسؤول عن توليد الخطوات حتّى الانتهاء عند أبسط المُكوّنات:
export function getStepsForLandmarks(
landmarks: CephaloLandmark[], removeEqualSteps = true
): CephaloLandmark[] {
return uniqWith(
flatten(map(
landmarks,
(landmark: CephaloLandmark) => {
if (!landmark) {
console.warn(
'Got unexpected value in getStepsForLandmarks. ' +
'Expected a Cephalo.Landmark, got ' + landmark,
);
return [];
}
return [
...getStepsForLandmarks(landmark.components),
landmark,
];
},
)),
removeEqualSteps ? areEqualSteps : areEqualSymbols,
);
};
يُسمّى هذا التّرتيب بالتّرتيب الطبولوجي (topological sort).
بالطّبع، تُعتبر هذه البيانات (خطوات التّحليل، ثمّ الخطوط والقيم الّتي يمكن حسابها) بيانات مُشتقّة، وكما قلنا فإنّ البيانات المُشتقّة يجب ألّا تٌحفظ ضمن مستودع البيانات، خطر لي في البداية أنّ هذه العمليّات الحسابيّة مُكلفة،
فتفكيك التّحليل هو عمليّة تستدعي نفسها (recursive)، لاحظ كيف يستدعي التّابع
getStepsForLandmarksنفسه على المُكوّنات الفرعيّة لكلّ مكوّن، حتّى نصل إلى مكوّن ليس له مكوّنات فرعيّة، مثل النّقاط.وثانيًا، في كلّ مرّة يُضيف فيها المُستخدم نقطة على الصّورة الشّعاعيّة، يقوم التّطبيق بـ:
- إيجاد كلّ الخطوط الّتي يمكن رسمها ثمّ رسمها على الصّورة
- إيجاد كلّ الزّوايا والأبعاد الّتي يمكن حسابها ثمّ حسابها وعرضها
وهذا يتضمّن أخذ كلّ مكوّنات التّحليل والمرور عليها واحدًا واحدًا ومحاولة معرفة إن كان ما عيّنه المستخدم من نقاط حتّى هذه اللّحظة يصلح لحساب القيمة المعنيّة؛ فهل يعني هذا أنّنا نحتاج لحسابها في كلّ مرّة نحذف فيها نقطة أو نُضيفها أو نغيّر موضعها؟ الحقيقة أنّ هذه هي الطّريقة الوحيدة لضمان بقاء القيم المُشتقّة منسجمة مع مواضع النّقاط في كلّ لحظة.
خطر لي لحلّ النّقطة الأولى، أي توليد خطوات التّحليل، فعل ذلك عند بناء البرنامج (compile time)، بالطّبع فإنّ JavaScript (وTypeScript بدورها) لغة ديناميكيّة ليس فيها مفهوم التّصنيف (compilation)، ولهذا سنحتاج ربّما لحفظ الخطوات بصيغة JSON ثمّ قراءتها، لكنّ هذا أوّلًا يعني الحاجة لإعادة فعل ذلك في كلّ مرّة أُغيّر فيها أيّ نصّ برمجيّ متعلّق بالتّحاليل، كما أنّه لن يصلح في المستقبل، لأنّني أخطّط للسّماح للمستخدم بإنشاء تحاليل مُخصّصة مبنيّة من نقاط مختلفة، وهذا يعني أنّنا سنحتاج لبناء الخطوات في وقتها على كلّ حال.
أمّا النّقطة الثّانية، فلا شكّ أنّها مُكلفة، وإن لم تكن كذلك، فهي مضيعة لكثير من وقت المُعالجة، الّذي كان سيُستغلّ في أشياء أخرى، فماذا لو كانت النّقطة المُضافة حديثًا لا تؤدّي إلى حساب قيمة جديدة أو رسم خطّ جديد؟ هل من طريقة لتوقّع ذلك؟
عندما يتعلّق الأمر بالأداء، فقد تعلّمت من خلال متابعتي لكثير من المُطوّرين الكبار في Facebook وGoogle أنّ تصوّرات المُطوّر عن الأداء ليست دقيقة دومًا، ولا تعكس تصوّر المُستخدم عن الأداء،
- فالعمليّات الحسابيّة في JavaScript سريعة جدًّا، فمحرّكات JavaScript تصبح أذكى وأسرع كلّ يوم، وإن كان تطبيقك بطيئًا فالسّبب غالبًا ليس في ما تجريه من عمليّات حسابيّة، بل في تعاملك مع DOM وما له علاقة بدورة رسم الإطار في الصّفحة (إعادة حساب التّخطيط layout والأنماط style والرّسم paint… إلخ.)
- هناك فرق بين الأداء المُجرّد (raw performance) والأداء المُحسوس (perceived performance)، أي الأداء الّذي يشعر به المُستخدم، يمكنك التّلاعب في كيفيّة تفسير المُستخدم لأداء تطبيقك وذلك بعرض مؤشّر التّقدّم أثناء القيام بالعمليّات الّتي تستغرق وقتًا طويلًا، ولهذا فائدتان:
- الأولى أنّه يجعل المستخدم يعلم بأنّ تطبيقك يقوم بشيء ما، وليس عالقًا.
- والثّانية أنّ وجود مؤشّر التّقدّم يجعل إدراك المُستخدم للزّمن المُستغرق أقلّ، مع أنّ عرض المؤشّر نفسه قد يجعل البرنامج يستغرق وقتًا أطول في معالجة العمليّة المطلوبة!
هذه التّقنيّة شائعة جدًّا ولا يكاد يخلو تطبيق منها، ولأضرب لك مثالًا، قارن بين حالة غياب المؤشّر ووجوه؟ أيّهما يقدّم تجربة استخدام أفضل برأيك؟
يعرض التّطبيق مؤشّر حالة يدور، وكما نعلم فإنّ رسم العناصر هو جزء من دورة الصّفحة، وJavaScript لغة أحاديّة المسلك، لا تستطيع القيام بأمرين في وقت واحد، وهذا يعني أنّنا لا نستطيع تدوير هذا المؤشّر بسلاسة لو كان المتصفّح مشغولًا بعمليّة مُكلفة، كقراءة الصّورة، الّتي غالبًا ما تكون كبيرة الحجم (نحو 5 ميغابايت). فكيف أمكنني الوصول إلى تدوير المؤشّر بسلاسة مع معالجة الصّورة في الوقت نفسه؟
توفّر المتصفّحات إمكانيّة إنشاء مسالك إضافيّة تعمل جنبًا إلى جنب مع الصّفحة الرّئيسيّة من خلال الواجهة البرمجيّة لـWeb Workers، استخدمت في هذه الحالة Worker منفصلًا تُرسل إليه الصّورة من الصّفحة الرّئيسيّة ليقوم بقراءتها وإعادتها للمسلك الرّئيسيّ الّذي تُنفّذ عليه عمليّات الرّسم وكلّ العمليّات التّقليديّة.
الحقيقة أنّ عمليّة إرسال البيانات بين المسلكين تتضمّن نقل جزء من المسلك الرّئيسيّ بصيغة آمنة وإعادة إسناده، كما أن إنشاء المسلك بحدّ ذاته يتطلّب عملًا إضافيًّا على مستوى نواة النّظام (kernel)، وهذا يعني أنّ ما قمت به يزيد من وقت المعالجة واستهلاك الذّاكرة، لكنّك عندما تقارن النّتيجة الحاليّة، بنتيجة تنفيذ كلّ العمليّات في مسلك واحد، والّتي تستغرق وقتًا فعليًّا أقلّ، فإنّك لا شكّ ستشعر أنّ البرنامج أكثر استجابة مع استخدام المسلكين، هذا هو الأداء المحسوس.
على العكس من ذلك، فإنّني وفي محاولة ساذجة، ولاعتقادي بأنّ استنتاج الخطوط القابلة للرّسم والزّوايا القابلة للقياس عمليّة مُكلفة، قمت بنقل كامل المنطق المُتعلّق بها إلى Worker آخر، يعمل في الخلفيّة ويتلقّى الأحداث المُتعلّقة بإضافة أو تعديل النّقاط، ليقوم بإرسال ما يمكن رسمه وحسابه مرّة ثانية إلى المسلك الرّئيسيّ، تبيّن أنّ عمليّة النّقل بين المسلكين مُكلفة أكثر من عمليّة الحساب نفسها، فالحساب على المسلك الرّئيسيّ كان يستغرق حوالي 30 ميلي ثانية في أسوأ الأحوال، وأمّا على المسلك المنفصل فقد وصل حتّى 600 ميلي ثانيّة.
النّقطة الأخيرة المُتعلّقة بالأداء إذًا، هي أنّ تتجنّب الاعتماد على حدسك وشعورك، بل قم بقياس أداء برنامج، استخدم أدوات المُطوّرين لحساب متوسّط عدد الإطارات بالثّانية، وقم بتحديد المناطق الّتي تلاحظ فيها انخفاضًا ملحوظًا في متوسّط عدد الإطارات، ألقِ نظرة على ما يحدث في هذا الموضع، وكرّر العمليّة.
قد تجد خلال عملك ضمن أدوات المطوّرين وقياس أداء التّطبيق صعوبةً في تتبّع مصدر المُشكلة، ولهذا أنصحك باستخدام Performance API الّتي تسمح لك بإضافة مُسمّيات واضحة بين تعليمات تطبيقك، تظهر هذه المُسمّيات بوضوح في أدوات المُطوّرين مع الزّمن الّذي استغرقته، وهذا ما فعلته لمقارنة الأداء في الحالة الأخيرة.
في هذا الفيديو قمت بإجراء مقارنة بين استنتاج الخطوط والزوايا مباشرةً في الصّفحة على المسلك الرّئيسيّ (main thread)، واستنتاجها في مسلك منفصل، وتبيّن أنّ كلفة النّقل إلى المسلك أكبر ممّا يبرّر إجراء العمليّة فيه، وقد استخدمت Performance API لإضافة مسمّيات للفترات الّتي تتمّ فيها العمليّات، كما تظهر في قسم Timeline في أدوات مطوّري Chrome. لاحظ الاختلاف الكبير في الوقت، بين 30 ميلي ثانية وبضع مئات ميلي ثانية.
لعلّك تتساءل عن سبب اهتمامي الشّديد بالأداء، الحقيقة أنّني لم أصل لهذه المرحلة من الهوس بالأداء إلّا بعد أن تراجع الأداء بشكل ملحوظ، فتعيين النّقاط أصبح يتأخر بضع مئات ميلي ثانية بحيث يستطيع أن يلاحظه المستخدم، وعندها بدأت بتحرّي السّبب، ووصلت لنتيجة مفادها أنّ استخدام Canvas لرسم العناصر، ومع أنّه سريع، إلّا أنّه يتعارض تمامًا مع طبيعة عمل React:
- فهي تعتمد على الأسلوب التّصريحيّ لوصف شكل الصّفحة في أيّ لحظة،
- وتقوم بحساب الاختلافات بين المُكوّنات لإعادة رسمها بأقل تكلفة ممكنة
وأمّا Canvas:
- فهي واجهة أمريّة (imperative API) صرفة، أيّ أنّنا عند استخدامها نأمر المتصفّح: ارسم الخطّ بين النّقطة كذا والنّقطة كذا، حرّك النّقطة من هنا إلى هناك… إلخ.
- كما أنّ عنصر Canvas هو عنصر مغلق على نفسه (opaque) ليس له خصائص تصف محتوياته، فتمثيله في HTML هو هكذا فقط:
<canvas />
وأمّا محتوياته فتأتي من JavaScript، وهي ليست إلا مجموعة من البكسلات، وهذا يعني أنّ React لا تستطيع حساب الاختلافات في خصائص عنصر <canvas />.
منذ اللّحظة الأولى الّتي استخدمت فيها مكتبة Fabric.js (الّتي تستخدم Canvas) لعرض الصّورة وترسيمها، فإنّني شعرت بهذا التّعارض، وكنت قد كتبت مُكوّن React خاصًّا يرفض أيّ تحديث له من خلال تغيير الوظيفة shouldComponentUpdate في دورة حياته لتعيد false دومًا، وأمّا التّغييرات فيتم تلقّيها في componentWillReceiveProps وإجراء حساب الاختلافات على الخطوط والزّوايا الّتي ترده يدويًّا باستخدام مكتبة deep-diff.
من الواضح أنّ هذا الحلّ ليس نظيفًا فهو يخالف سير مهمّة React ويقوم بإعادة كتابة أجزاء من هذه المهمّة، لكنّني كنت أقول لنفسي إنّ ما يهم هو النّتيجة، وليس الكيفيّة، ولكنّ الأداء أصبح سيئًّا بما لا يمكن تبريره، وعندها توقّفت عن العمل بحثًا عن حلّ، حتّى خطر لي استخدام SVG لعرض الصّورة ورسم الخطوط والزّوايا والنّقاط، والحقيقة أنّني تردّدت في ذلك، بين أن أخسر ما وصلت إليه من جهد وبرنامج يعمل على سوء أدائه، وأن أُقدم على استخدام SVG الّتي لم أكن أعرف عنها إلّا القليل وأبدأ بإعادة كتابة جزء كبير وأساسيّ في التّطبيق، الأمر الّذي قد ينتهي بالفشل. لحسن الحظ ليس عليّ الاختيار بين أحد هذين الأمرين، فـgit يجعل إجراء التّجارب والعودة إلى أيّ مرحلة في المشروع أمرًا يسيرًا، قمت بإنشاء فرع جديد اسمه svg، وبدأت بتغيير كامل المُكوّن السّابق جزءًا تلو جزء، بحيث أحافظ على طريقة استخدامه (external API)، مع تغيير طريقة عمله من الدّاخل (internal API)، حتّى وصلت إلى مرحلة رضيت فيها عن الأداء، وليس هذا فحسب، بل إنّ التّحوّل إلى SVG سمح لي باستخدام ملفّ الصّورة مباشرةً دون الحاجة إلى إعادة تحميله في Jimp وفكّ ترميزه (decoding) وإعادة جلبه من Worker، الأمر الّذي قلّص فارق تحميل الصّورة بشكل واضح. ليس هذا فحسب، بل إنّ التّخلّي عن مكتبة Fabric.js سمح بتخفيض حجم ملفّات التّطبيق في مرحلة البناء بشكل كبير.
لاحظ كيف أصبح النّصّ البرمجيّ أقصر بكثير، وأسهل للقراءة والفهم. كما أنّ مكوّنات SVG هي مكوّنات ذات خصائص يمكن لـReact حساب الاختلافات عليها ولعلّ هذا سبب تحسّن أداء التّرسيم بشكل أساسيّ.
قارن بنفسك بين أداء التّطبيق باستخدام Canvas أوّلًا ثمّ SVG ثانيًّا (لاحظ الاختلاف الكبير في سرعة تحميل الصورة، ثمّ في سرعة ظهور النّقاط والخطوط أثناء التّرسيم):
بعد أنّ رأيت هذا الاختلاف الملموس في الأداء، قمت بدمج فرع svg في الفرع الأساسيّ وهكذا تابعت بقيّة المشروع مُستخدمًا SVG، وهو ما تستخدمه النّسخة المُتاحة اليوم.
الخلاصة فيما يتعلّق بالأداء:
- لا تعتمد على حدسك، اختبر الأداء في أدوات المطوّرين
- الأداء مهمّ، لكن الأهمّ هو الأداء المحسوس
- انقل بعض العبء إلى Workers حيث يكون ذلك مناسبًا
- المشكلة في DOM manipulation غالبًا، وليست في العمليات الحسابيّة الصّرفة
- التّوابع النّقيّة تسمح بتوفير العمليّات الحسابيّة – مرحى للرّياضيّات مرّة أخرى!
- إذا كنت تستخدم React، أنصحك باستخدام SVG بدلًا من Canvas للرّسم
- لا تحارب المتصفّح، بل استفد ممّا يقدّمه، فهو غالبًا ذو أداء أفضل من أيّ طريقة بديلة
كتابة ملفّات تعريف الأنواع لمكتبات JavaScript
واحدة من المشكلات الّتي واجهتني مع TypeScript متعلّقة بالتّعامل مع المكتبات المكتوبة بـJavaScript، بالطّبع هذه المكتبات خالية من الأنواع، ولا يمكن لـTypeScript أن تُساعدك في تجنّب الأخطاء أو فهم العلاقات بين الكائنات فيها، ولهذا يتوفّر نوع خاصّ من ملفّات TypeScript، يُسمّى ملفّ التّعريف (definition file)، يُرفق مع بعض المكتبات بحيث يصف أنواع الكائنات والوحدات الّتي توفّرها هذه المكتبة كما لو كانت مكتوبة بـTypeScript.
المشكلة تكمن في أنّ ملفّات التّعريف هذه ليست متوفّرة لجميع المكتبات، وخصوصًا المكتبات غير شائعة الاستخدام، بالطّبع هي متوفّرة لـReact وRedux مثلًا (وتأتي مرفقة مع الحزمة نفسها بحيث لا تحتاج لجلبها من مصدر خارجي)، وأمّا المكتبات غير الشّائعة فهي لا توفّر ذلك، ولذا تطوّع بعض المساهمين بكتابتها ونشرها بصورة منفصلة على مستودع على GitHub يُسمّى DefinitelyTyped، ووُفرّت أداة تقوم بالبحث عن هذه الملفّات وتثبيتها بحيث تستطيع TypeScript استخدامها.
للأسف، سبّب هذا مشكلة أخرى، وهو كون هذه الملفّات غير مرفقة برقم إصدار، وهذا قد يؤدّي إلى مشكلات ناجمة عن الاختلاف بين ما تراه TypeScript ممّا يُقدّمه ملفّ التعريف، وما هو موجود فعلًا في المكتبة ولكن بإصدار أحدث أو أقدم. بدأ فريق TypeScript بحلّ هذا بتوفير ملفّات التّعريف على npm نفسها مسبوقًا بـ@types/، وهكذا أصبح بالإمكان اختيار إصدار موافق للإصدار الّذي نستخدمه من المكتبة.
مع ذلك، عانيت من غياب ملفّات التّعريف لعدّة مكتبات استخدمتها، ومنها redux-undo الّتي توفّر إمكانيّة التّقدّم والتّراجع أثناء ترسيم الصّورة، وكان Visual Studio Code يُشير إلى خطأ عدم وجود المكتبة المعنية، وهذا يعني أنّه بناء التّطبيق في مرحلة الإنتاج سيفشل، لذا اضطررت إلى كتابة ملفّ التّعريف بنفسي.
تكرّر الأمر نفسه مع مكتبة deep-diff الّتي استخدمتها في مرحلة سابقة من التّطوير ثمّ استغنيت عنها، وكذلك مع scroll-into-view-if-needed ومع idb-keyval.
المساهمة في المشاريع مفتوحة المصدر
أثناء كتابة هذه الملفّات قلت لنفسي: من الأفضل لو كانت هذه الملفّات مرفقة مع الحزمة ذاتها، هذا سيُنهي مشاكل الاختلافات في الإصدارات، كما أنّه سيكون مُفيدًا للآخرين، حيث سيمكنهم استخدام المكتبة في TypeScript بمجرّد تثبيت المكتبة ودون أيّة أجراءات خاصّة، لذا قمت بطرح الملفّات الّتي قمت بكتابتها لأصحاب المكتبات (1، 2، 3، 4)، وقد تمّ قبول بعضها لتصبح جزءًا من المكتبة الأساسيّة، وما زلت أنتظر قبول الأخرى، وبعضها كان يحتاج بعض الإصلاحات، ومن الجميل أنّ هناك من قام بمتابعة مساهمتي وتحسينها، وهذا يدلّ على تصاعد شعبيّة TypeScript 😄.
نشر التّطبيق (Deployment)
تطوير تطبيقات الويب أمرٌ معقّد، إذ لا يكفي أن يكون منطق تطبيقك سليمًا، والحقيقة أنّ معظم التّعقيد لا يكمن في منطق التّطبيق بقدر ما يكمن في جعل التّطبيق يعمل مع عدّة متصفّحات على ما فيها من اختلافات وميّزات ناقصة أو غير مُنفّذة وفق المعايير. هذا الأمر مُهمّ لأنّ المستخدمين يفضّلون متصفّحات مختلفة، وأنت كمطوّر تسعى لتغطية أكبر عدد من المستخدمين، بغض النّظر عن المتصفّح الّذي يستخدمونه.
سأعترف أنّني لم أولِ هذا الجانب أهمّية كبيرة، ربّما لنقص خبرتي في هذا المجال، أو ربّما لاعتقادي أنّ تطبيقي لن يكون شعبيًّا، ولديّ رفاهيّة التحكّم في البيئة الّتي سيعمل بها، بأن أطلب من المستخدم الانتقال إلى متصفّح آخر.
هذا الأمر سيئ طبعًا، فهو يعيد ذكريات «هذا الموقع مصمّم ليعمل على Internet Explorer» في التّسعينات، لكن المفارقة تكمن في أنّ السّبب معاكس تمامًا، فهذه المرّة المتصفّح المُستهدف لتطبيقي هو المتصفّح الأكثر التزامًا بالمعايير! أيّ أنّ Chrome أصبح يُطبّق معايير حديثة جدًّا بحيث يسبق منافسيه، وكذلك Firefox يسير على خطاه.
بالنّسبة للمستخدم، هذا غير مهمّ، ما يُحدّد نجاح تطبيقك هو أن يقدّم للمستخدم الخدمة الّتي صُمّم ليقوم بها، وهي في حالتي ترسيم الصّور السّيفالومتريّة وتحليلها، كلّ ما سوى ذلك غير مهمّ، ونجاحك كمطوّر يكمن في التزامك بهذه الفكرة.
المشكلة الجوهريّة تكمن في كيفيّة تطويرنا لتطبيقات الويب، فالمطوّر عادةً ما يستخدم جهازًا سريعًا، ونظام تشغيل حديثًا، وآخر نسخة من Chrome، وأمّا أجهزة المستخدمين فهي أبطأ وأقدم، ومتصفّحاتهم قد تكون قديمة أو مختلفة تمامًا، الحلّ لهذه المفارقة برأيي يكمن في إجراء الاختبارات المؤتمتة واليدويّة على أكبر عدد من أنظمة التّشغيل والمتصفّحات.
المشكلة الثّانية أنّني أعمل وحدي، وهذا يجعل قائمة الأشياء الّتي يجب القيام بها طويلة جدًّا لشخص واحد، وعليّ تحديد الأولويّات بدقّة، حتّى وإن كنت فعليًّا أستطيع حلّ كلّ المشكلات في التّطبيق وإضافة الكثير من الميّزات، فإنّ وقتي لا يسمح بذلك.
على أيّة حال، هناك الكثير من الأمور الّتي قمت بها لأصل لتجربة مقبولة على Chrome وFirefox على الأقل، وآمل في المستقبل أن أقوم بإجراء اختبارات مُتكاملة (end-to-end tests) باستخدام خدمات مثل BrowserStack أو SauceLabs، هكذا أستطيع تجربة التّطبيق بشكل مؤتمت مع كلّ إيداع، وعلى متصفّحات ليست موجودة على جهازي، وعندها فإنّ أيّ إصدار جديد لن يصل إلى مرحلة الإنتاج إلّا إن نجحت الاختبارات على المتصفّحات المُستهدفة، أجريت منذ فترة تجربة بسيطة لاختبار الواجهة البرمجيّة للتّعمية على الويب (WebCrypto API)، ولك أن تتوقّع من هو المتصفّح الّذي أخفقت الاختبارات فيه. 😉

اختبار مشروع على أكثر من متصفّح باستخدام SauceLabs
قمت أوّلًا بتحديد قائمة من الميّزات الّتي لا بدّ منها لعمل التّطبيق، ثمّ تطبيق اكتشاف الميّزات (feature detection) باستخدام مكتبة Modernizr، وعند وجود ميزة واحدة أو أكثر مفقودة في المتصفّح، يُعرض مربّع حوار يطلب من المستخدم تحديث متصفّحه، أو الانتقال إلى متصفّح آخر متوافق.
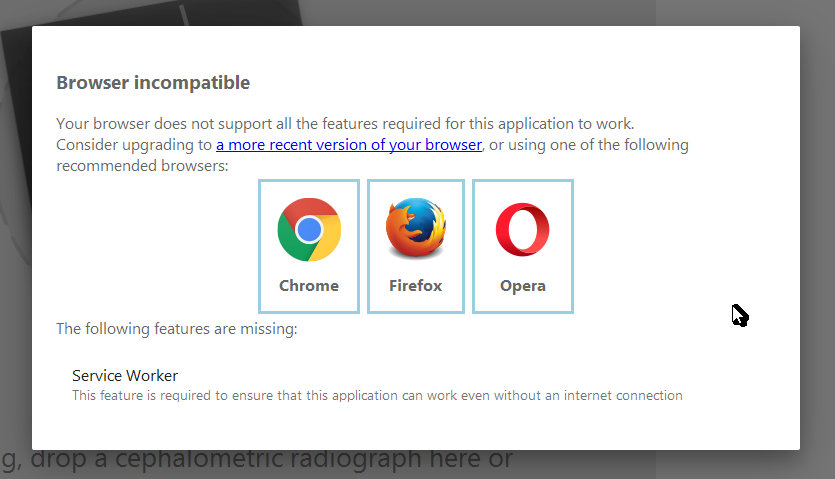
مربّع حوار التّحقّق من توافق المتصفّح
هذا الحلّ مؤقّت وغير مثاليّ، لأنّه يتجاهل تمامًا إمكانيّة سدّ بعض النّواقص في المتصفّحات باستخدام ما يُسمّى Polyfills، وقد بدأت بالفعل باستخدام polyfills للتّعويض عن نقص بعض الميّزات الحديثة جدًّا مثل ResizeObserver API وElement.scrollIntoViewIfNeeded()
التّطبيق ثابت بالكامل (static) ولا يحتاج لخادوم مُخصّص، فهو ليس سوى ملفّ HTML مع بعض الصّور وملفّات JavaScript وCSS، ولذلك قمت باستضافته على صفحات GitHub، المرتبطة بنطاقي الخاصّ. وأمّا شهادة SSL والتّخزين المؤقّت فتوفّرهما خدمة Cloudflare لكامل نطاقي.
شهادة SSL ضروريّة لاستخدام HTTP/2 في جميع المتصفّحات، وكذلك لتأمين عمل التّطبيق دون اتّصال باستخدام الواجهة البرمجيّة لـService Worker، الّتي يُشترط لاستخدامها توفّر التّطبيق على نطاق آمن، وهذا اتّجاه عامّ بدأت المتصفّحات بتنبيه لدفع أصحاب المواقع إلى استخدام SSL للتّعمية بين الخادوم والعميل، فاستخدام الويب بدون تعمية يعرّض المستخدم لهجمات الرّجل في الوسط (man-in-the-middle attacks) ويتيح لأي شخص على الشّبكة التّنصّت وسرقة البيانات أو تعديلها بين الطّرفين. لم يستغرق إعداد شهادة SSL مع Cloudlfare على موقعي سوى خمس دقائق، ولم يكلّف سنتًا! إن كنت لا تستخدم SSL، رجاءً استخدم Cloudflare الآن!
للأسف لا يمكن استخدام نطاق خاصّ مع صفحات GitHub وتحويل المستخدم إلى نسخة HTTPS من الموقع بشكل تلقائيّ باستخدام إعادة التّوجيه في HTTP (HTTP Redirects)، ولحلّ هذه المشكلة كان عليّ اللجوء إلى حلّ التفافي، وذلك بإعادة توجيه المستخدم عن طريق JavaScript. بودّي لو أستطيع استخدام خادوم على DigitalOcean، لكنّ التّعاملات الماليّة على الويب من داخل سوريّا رابع المُستحيلات!
أداء التّطبيق عبر الشّبكة
يُبنى التّطبيق ويُحزّم باستخدام Webpack 2، وهو أداة قويّة جدًّا تتيح لك أتمتة وإنجاز مهامّ كثيرة، لكنّ ذلك يأتي على حساب تعقيد عمليّة البناء وإطالتها، كما أنّ توثيق Webpack كما هو معلوم بالغ السوء!
This Child's Reaction When She Finally Gets Webpack To Run Will Melt Your Heart
— BuzzFeedJS (@BuzzFeedJS) March 25, 2016
Meet The Developer Who Got Webpack Up And Running And Didn't Even Blog About It
— BuzzFeedJS (@BuzzFeedJS) October 4, 2016
المشكلة الأساسيّة اليوم في أدوات التّطوير مثل Webpack وGulp أنّها صُمّمت لتحلّ مشكلة طلبات HTTP الكثيرة الّتي كانت تُبطِئ تحميل الموقع، وذلك بجمع عدّة ملفّات معًا وتقليصها، لأنّ كلفة نقل الملفّات الصّغيرة أكبر من كلفة نقل ملفّ واحد كبير، وهذا لأنّ كلّ طلب في HTTP/1 يُضيف عبئًا على الشّبكة بإرسال الطّلب وعودته (roundtrip)؛ إلّا أنّ هذا تغيّر تمامًا مع HTTP/2، ففي HTTP/2 يُعاد استخدام الاتّصال نفسه لجلب عدّة ملفّات من الخادوم، بل وعدّة ملفّات في وقت واحد في نفس الاتّصال (multiplexing)، وهذا بالطّبع يعني أنّ نقل ملفّ واحد كبير لم يعد شيئًا غير مُفيد فحسب، بل أصبح شيئًا غير مُفضّل (anti-pattern)، لأنّ المتصفّح لن يبدأ بتفسير الملفّ الكبير حتّى اكتمال تحميله، بينما باستطاعة المتصفّح تفسير الملفّات الصّغيرة المنفصلة الّتي ترده تباعًا. إن كنت مهتمّا بموضوع بروتوكولات النّقل على الشّبكة فأنصحك وبشدّة بقراءة كتاب High Performance Browser Networking لـIlya Grigorik من Google.
أعتقد أنّ أدوات التّطوير لم تصل بعد لمرحلة الاستفادة الكاملة من HTTP/2، مع أنّه لوحده قادر على تحسين تجربة استخدامنا للويب بشكل كبير. قمت بتجربة إضافة لـWebpack، تُسمّى Aggressive Splitting Plugin، تُقسّم التّطبيق إلى حزم صغيرة مناسبة لـHTTP/2، إلّا أنّني واجهت مشكلات في بناء التّطبيق، وهذا متوقّع مع كونها لا تزال في مرحلة تجريبيّة.
إلّا أنّ شيئًا واحدًا لم يتغيّر مع HTTP/2، وهو أنّ تقليص الملفّات (minification) لا يزال أمرًا مرغوبًا، فكلّما قلّ حجم البيانات المنقولة بين الخادوم والمتصفّح، كان وصول تطبيقك إلى المستخدم أسرع، كما أنّ التّقليص لا يُقلّل فقط من حجم الملفّات، بل إنّه يُحسّن من أداء التّطبيق أيضًا، وذلك بحذف الكثير من العبارات المُصمّمة لتُساعد المستخدم أثناء التّطوير، وأمّا بالنّسبة للمُستخدم فهي غير مُهمّة، ستلاحظ ذلك في الكثير من المكتبات الحديثة مثل React وRedux وغيرها.
إلّا أنّ لدينا مُشكلة أخرى في تقليص الملفّات، وهي أنّ الأداة الأكثر شيوعًا لتقليص JavaScript، وهي UglifyJS، أصبحت قديمة، فهي مُصمّمة لتقليص الإصدارات القديمة من JavaScript فقط، مع أنّ المتصفّحات الحديثة أصبحت في معظمها تفهم ES6، وهذا يعني أنّنا نُضيف الكثير من العبء عند تحويلها لصيغة أقدم.
في الإصدارات الأولى من WebCeph كنت أستخدم UglifyJS، لكنّني علمت بوجود مشروع يعمل عليه فريق Babel نفسه، يُسمّى Babili، وهو يهدف لتقليص الملفّات لإصدارات حديثة من JavaScript باستخدام Babel؛ وعندها خطر لي سؤال: لماذا لا يوجد شيء مثل Autoprefixer لـJavaScript؟ لماذا لا أستطيع تحديد ما المتصفّحات الّتي أريد لتطبيقي أن يتوافق معها، ليقوم Babel بتحويل مشروعي إلى نسخة تتوافق مع أقدم نسخة مطلوبة من المتصفّحات؟ لحسن الحظ، تبيّن أنّ الفريق نفسه يعمل على ذلك في مجموعة إضافات لـBabel تُسمّى babel-preset-env، وهي تعمل بأسلوب مشابه تمامًا لـAutoprefixer. إليك ملفّ ضبط Babel في WebCeph، لاحظ كيف أستهدف أحدث إصدارين من Chrome وأحدث 5 إصدارات من Firefox حاليًّا:
{
"sourceMaps": "both",
"presets": [
[
"env",
{
"modules": false,
"browsers": [
"last 2 Chrome versions",
"last 5 Firefox versions"
]
}
],
"react",
"stage-3"
],
"env": {
"production": {
"plugins": [
"transform-runtime",
"minify-empty-function",
"transform-inline-environment-variables",
"transform-node-env-inline",
"transform-remove-console",
"transform-remove-debugger"
],
"presets": [
"react-optimize"
]
},
"sourceMaps": false
}
}
بالطّبع عليك أن تكون حذرًا في تبنّي هذا النّهج، لا أنصحك باتّباع هذا إن كنت تُصمّم موقع ويب، وأمّا إن كنت تبني تطبيق ويب حديثًا، ويستخدم ميّزات حديثة في المتصفّح، فأغلب الظّنّ أنّ المتصفّحات الّتي تستهدفها تفهم ES6 على كلّ حال.
لاحظ أنّ المشروع مكتوب بـTypeScript، الّتي تحوّل إلى JavaScript، ثمّ تحوّل إلى JavaScript مُقلّصة باستخدام Babel! مرحبًا بك في عالم تطوير الويب في عام 2016!
بإمكاننا تحسين أداء التّطبيق أكثر، فكما يقول Ilya Grigoryk في كتابه: «لا بِت أسرع من بت لا يُنقل»، بمعنى أنّ عليك كمطوّر تجنّب نقل البيانات ما أمكن بين الخادوم والمتصفّح، وإذا أستطعت أن تجعل تطبيقك يعمل بلا اتّصال تمامًا، فهذا رائع!
لحسن الحظّ تطبيقي ثابت (static) كما قلت، وهذا يجعل تحقيق عمله بلا اتّصال غايةً في السّهولة باستخدام Service Worker، وفي الحقيقة تتوفّر إضافة ممتازة لـWebpack تقوم بهذا الغرض. لأضعك بالصّورة، فإنّ جعل تطبيقي يعمل بلا اتّصال، ويحدّث نفسه تلقائيًّا، لم يُكلّفني سوى 25 سطرًا برمجيًّا، بما في ذلك السّطور الفارغة! وهكذا أصبح بإمكاني الانتقال بحاسبي المحمول إلى الجامعة وترسيم صور المرضى خلال دقائق وفي نفس الجلسة!
بالطّبع Service Worker يتيح القيام بأمور أضخم وأعقد من ذلك بكثير، وأعتقد أنّه سيكون واحدًا من أهمّ الإضافات إلى تاريخ الويب، وسيفتح أمام البلدان «النّامية» استخدام تطبيقات الويب كما لو كانت تطبيقات أصليّة (native). بإمكانك اعتبار Service Worker خادومًا وسيطًا (proxy server) يعمل ضمن المتصفّح، يعترض الطّلبات من موقعك ويفعل ما يشاء بها، فبإمكانه تخزينها مؤقتًا واستعادتها لاحقًا، وبإمكانه الرّد بدل الخادوم في غياب الشّبكة أو تخزين الطّلبات إلى حين عودة الشّبكة ثمّ إرسالها وغير ذلك.
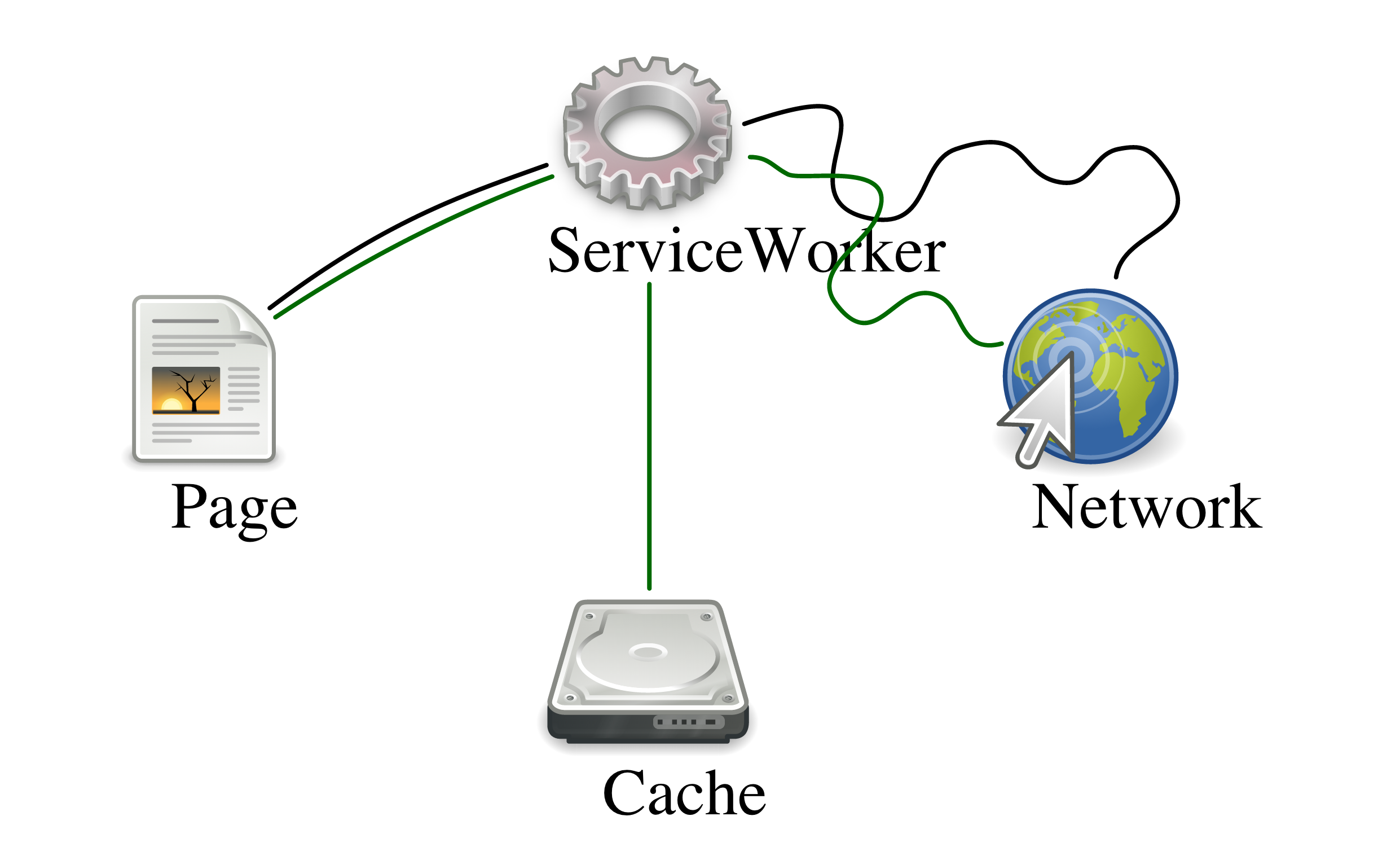
Service Worker يعمل عمل خادوم محلّيّ يعترض الطّلبات من تطبيقك
خارطة الطريق
على المدى القريب، لديّ الكثير من الأفكار الّتي ستحسّن من تجربة استخدام التّطبيق وتجعله يوفّر خدمة حقيقيّة لأطباء تقويم الأسنان، بحيث يصبح أداة يُمكن الاعتماد عليها بشكل يوميّ، ومنها على سبيل المثال لا الحصر:
- كتابة اختبارات الوحدات (unit tests) لجميع أجزاء البرنامج، فالاختبارات هي الطّريقة الوحيدة لضمان إمكانيّة تطوير البرنامج واستمرار صحّة منطقه في نفس الوقت، دون خوف من أن يؤدّي أي تعديل على هيكل البرنامج إلى نتائج خاطئة أو تصرّف غير متوقّع من المُستخدم. بالطّبع فإنّ استخدام TypeScript يقلّل من احتمال الخطأ، وكذلك الالتزام بالبرمجة التّابعيّة وتدفّق البيانات بجهة واحدة، لكن هناك أجزاء من البرنامج، كالتّحاليل وكيفيّة حساب القيم وتفسيرها، لا علاقة لها بهذه المفاهيم، ولا بدّ من اختبارها لإثبات صحّة عملها.
- إتاحة عمل التّطبيق بلا اتصال بالإنترنت (تمّ)
- تصدير الصور والنتائج (أولويّة): حاليًّا لحفظ نتائج التّرسيم أقوم (أنا وأصدقائي 😄) بالتقاط صورة للشّاشة لجدول نتائج التّحليل، وبالطّبع فهذا حلّ غير عمليّ، ولذلك أقوم الآن بكتابة صيغة ملفّ خاصّ (File format) يسمح بحفظ جميع بيانات الترسيم والصورة في ملفّ واحد يمكن إسقاطه إلى ساحة العمل في التّطبيق وعرض النّتائج والتّحاليل كما كانت بالضّبط عند تصدير الملفّ. (تم)
- تكبير الصورة وتصغيرها
- إتاحة رسم الخطوط يدويًّا
- إتاحة إزاحة النقاط بالفأرة أو لوحة المفاتيح (dragging/nudging)
- إتاحة تحديد نسبة تكبير الصّورة (scale factor) (أو ببساطة: ما عدد البكسلات الموافقة لـ1 سم على الصّورة؟) ليكون بالإمكان قياس المسافات على الصّورة وإجراء أي حساب خطّي.
- التراجع والتقدم (تمّ)
- تظليل النقاط والخطوط (تمّ)
أفكار كبيرة
توسعة البرنامج إلى برنامج فحص سريريّ متكامل
هذا أوّل مشروع جدّي أعمل عليه، وأستمتع بالعمل عليه، خصوصًا وأنّه يُقدّم لي ولأصدقائي، ولأي شخص حول العالم، فائدة حقيقيّة، ولهذا أنوي أن أستمرّ بتطويره ما استطعت، ومن ذلك تحويله إلى برنامج فحص سريريّ (clinical examination) مُتكامل يجمع معلومات المريض ونتائج التّحاليل المُختلفة ويقترح خطّة معالجة، لكنّ تحويل المشروع من مجرّد «أداة بسيطة لتسهيل العمل، أنشأتها على سبيل التّسلية» إلى مشروع «يعتمد عليه الكثير من أطباء التّقويم يوميًّا» هو ما يجعلني آخذ نتائج كلّ خطوة في التّطوير على محمل الجدّ، وهذا ينعكس على سرعة التّطوير بالطّبع.
التّرسيم التّلقائيّ الكامل للصّور!
ما من أحد عرضت عليه البرنامج إلّا وسألني هذا السّؤال بطريقة أو أخرى:
لماذا لا يقوم البرنامج بتعيين النقاط بنفسه؟
وعلى الفور تخطر في ذهني هذه الصّورة:

من الصّعب شرح الفرق بين السّهل وشبه المستحيل في علوم الحاسوب
لأستطيع شرح المشكلة للقرّاء غير المبرمجين: ما بنيته هو لعبة بلاستيكيّة على شكل صاروخ، وأنت تسألني: لماذا لم تبنِ صاروخًا نوويًّا؟
على أنّني أفهم تمامًا هذا الشّعور الكامن، بأن الحاسوب يجب، ويستطيع أن يفعل كلّ شيء لخدمتنا، وأنا أؤمن بهذا إيمانًا عميقًا، وفي الحقيقة أنا أتابع باهتمام تطوّر فروع الذّكاء الصّناعي وتعلّم الآلة، ولديّ أفكار مُبسّطة عن الشّبكات العصبيّة (neural networks) وكنت قد حضرت سلسلة Machine Learning Recipes على قناة Google Developers على YouTube، وهي سلسلة تشرح بأفكار مبسّطة وبتطبيقات عمليّة بعض مبادئ تعلّم الآلة، كما حضرت جزءًا من دورة تعلّم الآلة لـAndrew Ng، أحد أعلام تعلّم الآلة، على Coursera، وهي أيضًا مبسّطة.
هذا الفرع من علوم الحاسوب، وعلى تعقيده البالغ، يُصبح يومًا بعد يوم متاحًا لشريحة أوسع من المُتعلّمين، وبعض ذلك يعود إلى مسير تاريخ علوم الحاسوب نفسه، فالشّركات الكبرى مثل Google وFacebook وMicrosoft تُدرك تمامًا أنّ تعلّم الآلة سيكون عصب التّقنيّة في السّنوات القادمة، ولهذا فقد بدأت تستثمر في جعله متاحًا لشريحة أوسع، والحقيقة أنّ هذه الشّركات الثّلاث جميعها قد أتاحت جزءًا كبيرًا من ذكاءها الصّناعيّ للعموم وبرخصة مفتوحة المصدر؛ فـGoogle أعلنت عن ذكائها الصّناعيّ باسم TensorFlow، وقد قمت بتنزيله ومشاهدة بعض الدّورس عن كيفيّة استخدامه لتدريب شبكة عصبيّة على تصنيف الصّور (image classifier)، وهو أمر يصبح بسيطًا يومًا بعد يوم، وسأحاول البدء من هذه النّقطة، بكتابة برنامج مُبسّط يُصنّف الصّور الشّعاعيّة إلى صورة سيفالومتريّة جانبيّة، أو خلفيّة-أماميّة، أو صورة بانوراميّة.
عندما يتعّلق الأمر بتعلّم الآلة، فإنّني أواجه الكثير من التّحدّيات،
- الأولى هي الحظر التّقنيّ المفروض على سوريا، وصعوبة الحصول على بيانات للتّدريب (training sets)، وحتّى تنزيل TensorFlow كان بطريقة التفافيّة؛
- والثّانية هي حاجتي لتعلّم الأسس الرّياضيّة الّتي يقوم عليها هذا الفرع من علوم الحاسوب، وأقلّ ما يقال عنها إنّها ليست سهلة.
- والثّالثة هي حاجتي للتّعاون مع فريق، فهمها بذلت من جهد، فإنّ وقتي وطاقتي محدودان،
- والرّابعة هي أنّ المبادئ النّظريّة والأسس الرّياضيّة وحدها لا تكفي، فلا بدّ من تعلّم وإتقان التّطبيقات العمليّة المُتاحة على أرض الواقع لهذه المبادئ، مثل TensorFlow.
كما قلت قد تكون الخطوة الأولى هي معرفة نوع الصّورة، وبعد ذلك الانتقال إلى اكتشاف حدود العناصر في الصّورة، مثل حوافّ الجمجمة أو الشّفاه والجبهة، وقد اطّلعت على بعض تقنيّات التّعرّف على الحوافّ (edge detection) مثل Sobel filter.
ما الّذي تعلّمته من هذا المشروع؟
كما قلت، هذا أوّل مشروع له تطبيق يوميّ في حياتي، وأنا مُستمتع بالعمل عليه، وقد تعّلمت من خلاله الكثير:
1. البرمجة عمليّة تدرّجيّة (Iterative process)
بالطّبع فإنّ البرنامج لم يصل إلى هذه المرحلة فورًا، كما أنّ هذه المرحلة ليست نقطة النّهاية، وهذا مصدر الاسم «تطوير» (development)، لا يمكن لمشروع أن يصل إلى مرحلة يبلغ فيها منتهاه، فهناك دومًا مجال لإنجاز شيءٍ ما بصورة أفضل.
قد تضحك إن قلت لك إن هذه هي النّسخة الأولى من التّطبيق:
لكنّها الحقيقة!
عندما بدأت بالعمل كان كلّ ما أريده هو إثبات إمكانيّة الفكرة (proof of concept)، بدأت أوّلًا بملفّ HTML بسيط، فيه وسم script، واستخدمت مكتبة Fabric.js – لا Webpack، لا TypeScript، لا React، لا Redux ولا برمجة تابعيّة، كلّ ما في الأمر هو ملفّ HTML، وبعض السّطور البرمجيّة في script مُضمّن في الصّفحة!
أؤمن تمامًا بعبارة Addy Osmani، أحد مُطوّري الويب في Google:
First do it, then do it right, then do it better
لن تدرك عمق هذه العبارة إلّا إن مررت بتجربة تطوير مشروع برمجيّ بنفسك!
الوصول إلى هذه المرحلة من التّطوّر الذّهنيّ والنّفسيّ في تطوير البرامج أمرٌ ليس يسيرًا، فالمتعلّم الجديد يعتقد –لحماسه– أنّه يستطيع عمل أي شيء ولذلك يبدأ ببناء المشروع كما لو كان يبني نظام إطلاق صواريخ! وفي الحقيقة فإنّني كنت أقضي معظم وقتي في إعداد بيئة المشروع وتثبيت الحزم حتّى أفقد الحماس.
المفارقة تكمن في أنّ ازدياد خبرتك كمطوّر يجعلك تُدرك حدود قدرتك الذّهنيّة، عقلك ليس قادرًا على تحمّل كلّ هذه الأعباء في وقت واحدً، حتّى لو كنت قادرًا على إنجازها، فإنّك ستبلغ مرحلة من التّعقيد تسأم فيها مجرّد التّفكير في متابعة العمل. لحلّ هذه المشكلة عليك أن تؤمن أن البرمجة، كأي مهارة أخرى، عمليّة تدرّجيّة (iterative)، ستبدأ أوّلًا بإنجاز المشروع بأبسط صوره، وستقع في أخطاء كثيرة، وإن لم تقع في خطأ ما، فهذا لأنّك لا تقوم بإنجاز أيّ شيء مُفيد فعلًا! لحسن الحظّ، البشر أذكياء بما يكفي، وقد اخترعوا أدوات تجعل الخطأ جزءًا طبيعيًّا من مسيرة مشروعك، من هذه الأدوات git!
جزء من المشكلة يكمن أيضًا في نظر المُتعلّم الجديد إلى النّصّ البرمجيّ، بشكل ما كانت لديّ فكرة أنّ كمّيّة النّصّ البرمجيّ الّذي أكتبه مرتبطة بذكائي ارتباطًا خطّيًّا، وأنّ ازدياد هذه الكمّيّة يجعل المشروع أفضل أو أكثر فائدة.
يحتاج الأمر الكثير من مغالبة الغرور لتصل إلى المرحلة التّالية، وهي أنّ النّصّ البرمجيّ الّذي تكتبه ليس له القيمة الّتي تظنّها، بل على العكس، فإنّ كتابة نصّ أقلّ تعني برنامجًا أقل عرضة للخطأ، وهذا ما يُدركه تمامًا كبار المُطوّرين.
في هذه المرحلة تدرك أنّ الجزء ذا القيمة الحقيقيّة في مشروعك هو هندسته (architecture)، ولهذا يُسمّى المُطوّر «مهندس» برمجيّات (Software engineer).
كلّما ازددت خبرة في تطوير البرامج، قل الوقت الّذي تُنفقه في كتابة النّصّ البرمجيّ، وازداد الوقت الّذي تُنفقه في التفكير في هيكل المشروع وانعكاسات ذلك على إمكانيّة تطويره وتوسعته في المستقبل.
ولعلّ جزءًا آخر من المشكلة نابع من قلقك من كيفيّة نظر الآخرين لك:
إذا كنت بالفعل مبرمجًا ماهرًا، فلماذا لم تُنجز شيئًا مُفيدًا حتّى الآن؟
لماذا يستغرق إعداد برنامج سهل كهذا كلّ هذا الوقت؟ كنت أظنّك مُبرمجًا مُحترفًا!

النّاس يظنّون أنّ الأمر متعلّق بكتابة البرنامج، والحقيقة أنّ الهندسة هي المُهمّة! الأمر أشبه بأن تقول لشاعر: كتابة الشعر أمرٌ سهل، فكلّ النّاس يستطيعون الكتابة!
2. الخطأ جزء من مسيرة التّطوير
سأعيد تكرار الفكرة مُجدّدًا لأهمّيتها، قد تظنّ أنّني عندما بدأت العمل كنت أعلم مُسبقًا كيف أقوم بحساب الزّوايا بين الخطوط، لكن الحقيقة أنّني غيّرت الجزء المُتعلّق بكيفيّة حساب الزّوايا رياضيًّا 4 مرّات،
- ففي المرّة الأولى كنت أعتقد أنّ حساب الزّاوية ببساطة يمكن إنجازه عن طريق التّوابع المثلّثيّة النّاشئة عن العلاقة بين مُستقيم والمحور x؛
- وفي المرّة الثّانية، تبيّن لي أنّ هذه الطّريقة تُعطي نتائج خاطئة لبعض الزّوايا، فحاولت حساب الزّوايا عن طريق إيجاد مثلّث يجمع النّقاط الثّلاث معًا ثمّ استخدام قانون جيب التمام (law of cosines) لإيجاد الزّاويا المطلوبة بالاعتماد على أطوال أضلاع المُثلّث المعني؛
- ثمّ تبيّن لي أنّ بعض الزّوايا في الصّور السّيفالومتريّة لا يمكن أن تقع في مثلّث مُشكّل من النّقاط المعروفة، وهكذا انتهيت بطريقتين لحساب الزّوايا، الأولى والثّانية، واحدة منها تُعطي نتائج خاطئة بعض الأحيان، ونتائج صحيحة في أحيان أخرى.
عندها توقّفت تمامًا عن العمل، وبدأت بالبحث عن طريقة موحّدة لحساب الزّاوية المقصودة، وتبيّن لي أنّ هناك اختلافًا في كيفيّة نظرنا نحن البشر إلى الزّوايا (أو ربّما نحن أطباء التّقويم بالذّات)،
- فعندما نقول الزّاوية بين الخطّين SN وNA، فنحن نعني الزّاوية بين الشّعاعين NS وNA، لكنّ بديهتنا وذاكرتنا تتدخّل لتُصحّح مفهوم «الخطّ» إلى «شعاع»!
- بالنّسبة للحاسوب، لا شيء بديهيّ، ولا يمكن أن تُعامل شعاعًا على أنّه خطّ، فهذا يحذف معلومة الجهة وهي معلومة لا بدّ منها إذا أردنا حساب زاوية بين شعاعين، وذلك باستخدام الجداء النّقطي (dot product).

الجداء النقطي لشعاعين
- فعندما نقول الزّاوية بين الخطّين SN وNA، فنحن نعني الزّاوية بين الشّعاعين NS وNA، لكنّ بديهتنا وذاكرتنا تتدخّل لتُصحّح مفهوم «الخطّ» إلى «شعاع»!
3. ليس عليك تعلّم كلّ شيء، لكن عليك الاحتفاظ بالقدرة على التّعلّم
عندما بدأت العمل على WebCeph، لم أكن قد استعملت سابقًا أيًّا ممّا يلي:
- TypeScript
- Canvas API
- SVG
- Drag and Drop API
- Resize Observer API
- Web Workers
- Service Worker
لكنّني كنت أعلم تمامًا بوجود هذه التّقنيات، ولعلّ سبب ذلك هو متابعتي المستمرّة لمعايير الويب الجديدة ولمواقع دروس التّطوير ومدوّنات بعض مُطوّري الويب البارزين وتغريداتهم، ولهذا فإنّني كنت أعلم في الغالب (وليس دومًا) ما الواجهة البرمجيّة المناسبة لإنجاز غرض ما، وكنت أعلم بخصائص كلّ واجهة ودعمها في المتصفّحات وانعكاسات استخدامها على أداء التّطبيق.
عندما تبدأ تعلّم تطوير الويب، عليك أن تتخلّى كُلّيًّا عن فكرة «أنهيت تعلّم كذا»، قد يُصيبك هذا بالإحباط، لكن لا مفرّ من هذه الحقيقة، ففي كل يوم هناك عشرات المقالات والنّتائج الّتي تُنشر، وفي كلّ شهر أقرأ عن اقتراح واجهة برمجيّة جديدة في الويب؛ أعلم تمامًا أنّني لن أستطيع تعلّمها، بل ولن أستفيد من ذلك، ولكنّني أعلم أيضًا أنّني قد أحتاج بعضها يومًا ما، ويكفيني أن أعلم بوجودها لأتعلّمها عند الحاجة.
إن كنت وصلت إلى هذه الفقرة وقرأت كامل التّدوينة، فلربّما تستحقّ جائزة أكثر النّاس الأحياء صبرًا على القراءة!
جدول المحتويات